| Новые программы oszone.net |
В первой части этого цикла из четырех частей, мы рассмотрели, какую операционную систему использовать для многосайтовых CCR кластеров. Мы рассмотрели растянутые и нерастянутые подсети и настройку сетевых карт. В этой части мы продолжим с того места, на котором остановились в предыдущей части. Мы рассмотрим стратегии растянутых сайтов Active Directory и рекомендуемые значения таймаута для сетевой задержки и тактовых импульсов (Network Latency и Heartbeat). Растянутый сайт Active DirectoryНезависимо от того, используете ли вы Windows Server 2003 или Windows Server 2008 в качестве основной операционной системы для своих серверов Exchange 2007, узлы кластера CCR всегда должны располагаться на одном сайте Active Directory (AD). Это означает, что, хотя узлы могут находиться в разных подсетях, вам все равно нужно растянуть AD сайт, к которому они принадлежат, между двумя центрами данных. Некоторые из вас, вероятно, слышали, что кластеры Windows Server 2008 Failover Clusters поддерживают узлы, расположенные в различных сайтах AD, и хотя это правда, Exchange не может располагать узлы CCR кластера на различных сайтах AD. Поскольку узлы кластера CCR должны принадлежать одному сайту AD, этот AD сайт необходимо растянуть между двумя центрами данных. Для роли сервера Hub Transport это может означать, что сообщения, отправляемые и принимаемые пользователями, чьи почтовые ящики хранятся на расположенном в основном центре данных CMS, могут теоретически приниматься с и отправляться на серверы Hub Transport (HT) в резервном центре данных. То же самое подходит и для таких клиентских запросов Exchange как автообнаружение (Autodiscover), OWA, EAS, POP3, и IMAP запросы/подключения к Client Access Servers (CAS). К тому же, LDAP/auth запросы на серверы глобальных каталогов (GCs) могут также передаваться на серверы в резервном центре данных. Как вы можете себе представить, это может генерировать большой объем трафика между центрами данных. Это особенно верно для серверов HT и CAS, а клиент Outlook использует MAPI по RPC для взаимодействия с серверами почтовых ящиков Exchange 2007 Mailbox. Однако вы можете заблокировать подключения/запросы, идущие на серверы в резервном центре данных. Что касается подписки сообщений с CMS на любой HT сервер в сайте AD, вы можете использовать Set-MailboxServer команду с -SubmissionServerOverrideList параметром для указания того, какие серверы Hub Transport должны использоваться. Таким образом, вы сможете исключить HT серверы, расположенные в резервном центре данных, несмотря на то, что они принадлежат одному AD сайту. Если/когда произойдет катастрофа в основном центре данных, в результате чего нужно будет обходить отказ на резервном центре данных, просто обновите список замены подписки, чтобы он включал лишь серверы HT в резервном центре данных. Чтобы заблокировать запросы/подключения CAS сервера для отправки на серверы в резервном центре данных, вы можете воспользоваться механизмом компенсации нагрузки. Если у вас большая среда, велика вероятность того, что вам придется, либо применить решение на базе аппаратных средств, либо на основе WNLB (смотреть эту статью о том, как компенсировать нагрузку серверов CAS). Если дело обстоит именно так, вот, что нужно сделать:
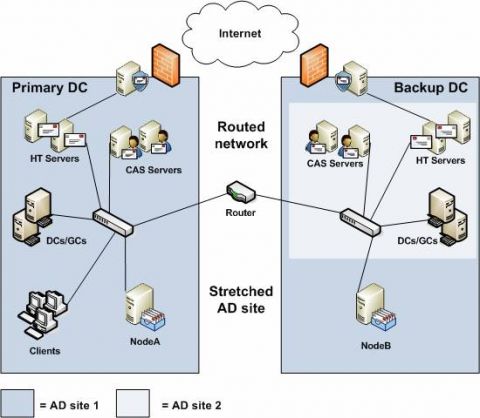
Использование двух сайтов Active Directory в резервном центре данныхЧтобы устранить возможность взаимодействия серверов и клиентов основного центра данных с серверами Exchange 2007 и GCs в резервном центре данных, вы можете создать дополнительный сайт AD в резервном центре данных, а затем переместить все серверы, за исключением Windows Failover Cluster, на котором установлена роль пассивного Mailbox, на этот сайт AD, как показано на рисунке 1.
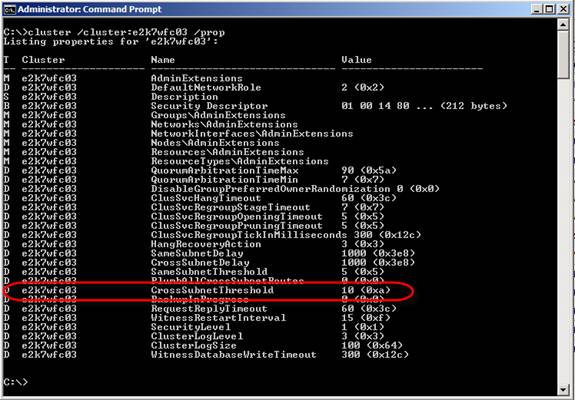
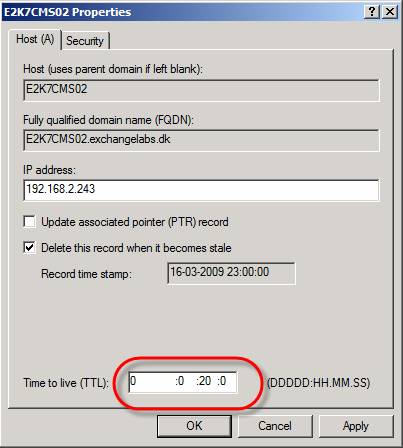
Рисунок 1: Два AD сайта в резервном центре данных Когда случится катастрофа, основной центр данных выполнит обход отказа на резервный центр данных. Далее нужно будет переместить серверы с второго сайта AD (AD сайт 2) на растянутый AD сайт (AD сайт 1), предоставив каждому серверу IP адрес в подсети растянутого AD сайта или путем изменения дефиниций AD сайта в оснастке Active Directory Sites and Services MMC. Некоторые из вас, возможно, подумают, что было бы проще переместить CMS на второй AD сайт, но это предоставит возможность HT серверу повторно предоставлять сообщения на CMS, что обернется потерей данных во время обхода отказа и не является поддерживаемым методом. Значения таймаута для сетевой задержки и тактового импульса (Network Latency и Heartbeat)Во время установки многосайтового CCR кластера вы должны попытаться удерживать сетевую задержку между центрами данных менее 500 миллисекунд (мс). Учитывая вышесказанное, вы можете просто настроить агрессивность таймаутов тактовых импульсов, что поможет вам избежать бесполезных обходов отказа при возникновении временных сетевых проблем. По умолчанию количество пропущенных импульсов кластера настроено на 5 импульсов для обоих узлов, расположенных в одной подсети и узлов в различных подсетях (рисунок 2). При работе с многосайтовыми кластерами рекомендуется изменить это значение на 10 пропущенных импульсов (приблизительно 12 секунд). Рисунок 2: Стандартное значение для пределов подсети Чтобы изменить предел CrossSubnetThreshold на десять пропущенных импульсов вместо стандартных пяти, используйте следующую команду: cluster ClusterName /prop CrossSubnetThreshold=10 Можно проверить новое значение предела пропущенных импульсов с помощью следующей команды: Cluster.exe /cluster:<ClusterName> /prop Рисунок 3: Предел подсети изменен на 10 пропущенных импульсов Значения DNS Time to LiveПри перемещении CMS (во время запланированного обхода отказа) с узла кластера в одной подсети на узел кластера в другой, и возвращении в рабочий режим IP адреса и ресурсного имени сети, кластер обхода отказа сбрасывает таймер. После десяти минут, когда ресурсное имя сети и IP адрес расположены на кластере, выполняется обновление DNS записи. По умолчанию DNS Time to Live (TTL) значение для ресурсного имени сети составляет 20 минут. Это означает, что при достижении таймером значения в 10 минут, вам придется ждать еще 20 минут для получения DNS записи (рисунок 4). Добавьте к этому время, необходимое на применение обновлений ко всем контроллерам домена в организации. Кроме того кэшу преобразователя клиентской стороны на клиентах Outlook также потребуется некоторое время на обнаружение обновлений.
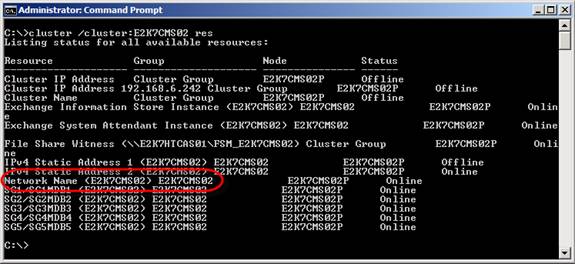
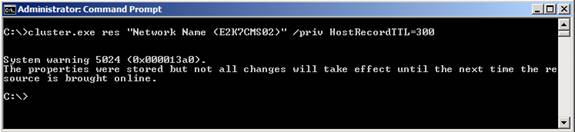
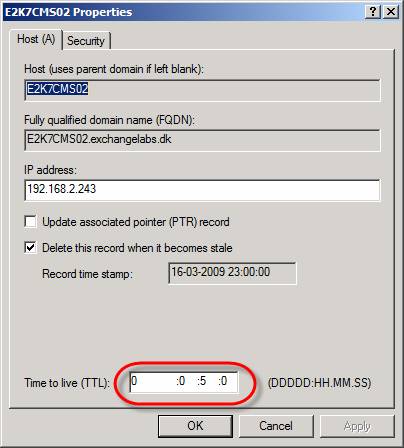
Рисунок 4: Стандартное DNS TTL значение для CMS в DNS диспетчере Плюс ко всему, 30 минут считается слишком длительным периодом в большинстве сред. Самой лучшей методикой считается смена значения DNS TTL на 5 минут. Для этого нужно сначала найти ресурсное имя сети кластера CMS. Это можно сделать с помощью следующей команды на одном из узлов кластера: cluster /cluster:<Name of CMS> resРисунок 5: Поиск ресурсного имени сети кластера CMS Теперь, когда у нас есть имя сети кластера, давайте изменим значение TTL на 5 минут. Для этого воспользуемся следующей командой: Cluster.exe res <CMSNetworkNameResource> /priv HostRecordTTL=300 Рисунок 6: Изменение TTL значения на 300 секунд (5 минут) Остановка и запуск Clustered Mailbox Server (CMS) с помощью Stop-ClusteredMailboxServer и Start-ClusteredMailboxServer команд или мастера Manage Clustered Mailbox Server. Примечание: хотя некоторые захотят так сделать, не стоит пытаться изменить DNS TTL через страницу свойств DNS записи в DNS диспетчере, поскольку параметры будут перезаписаны значением, настроенным для HostRecordTTL на узлах кластера при каждом обновлении DNS записи. Запись будет обновляться, когда CMS запускается, перемещается или возвращается в рабочий режим после отказа или обхода отказа. Теперь давайте проверим, что TTL для DNS записи изменено с 20 на 5 минут. Для этого мы открываем страницу свойств DNS записи ресурсного имени сети кластера CMS в DNS диспетчере на сервере DNS, как показано на рисунке 7.
Рисунок 7: Значение TTL изменено
Теги:
Exchange 2007, CCR-кластеры.
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|