| Новые программы oszone.net |
Visual Studio 11 сделает мейнстримовой поддержку гетерогенных вычислений за счет технологии C++ Accelerated Massive Parallelism (C++ AMP). Это позволит вам использовать преимущества акселераторов, например GPU (графических процессоров), для ускорения параллельных алгоритмов обработки данных. C++ AMP обеспечивает производительность и возможность переноса между аппаратными платформами без компромиссов в эффективности труда, которую вы вправе ожидать от современного C++ и пакета Visual Studio. Эта технология может дать выигрыш в скорости на несколько порядков по сравнению с использованием только CPU (процессора). На конференциях я обычно демонстрирую, как один процесс одновременно использует преимущества графических процессоров как от NVIDIA, так и от AMD, в то же время сохраняя способность работы на обычном процессоре в качестве резервного решения. В этом введении в C++ AMP, где много примеров кода, я исхожу из того, что вы будете читать каждую строку кода в статье. Этот код является основной частью статьи, и то, что показывается в коде на C++, не обязательно будет повторяться в тексте. Стартовый код и алгоритм-примерДля начала разберем простой алгоритм, с которым мы будем работать, наряду с необходимым стартовым кодом, чтобы подготовиться к переходу на последующее использование C++ AMP. Создайте пустой проект C++, добавьте новый пустой C++-файл (Source.cpp) и введите в него следующий код, не требующий пояснений (я использую номера строк, чтобы в тексте статьи было проще ссылаться на нужные строки, и те же номера строк вы найдете в прилагаемом к статье проекте, который можно скачать): 1 #include <amp.h> // заголовочный файл C++ AMP
3 #include <iostream> // для std::cout и т. д.
4 using namespace concurrency; // так меньше набирать кода :)
5 using std::vector;// то же самое; берется из <vector> в amp.h
6
79 int main()
80 {
81 do_it();
82
83 std::cout << "Hit any key to exit..." << std::endl;
84 std::cin.get();
85 }C++ AMP вводит целый ряд типов, содержащихся в различных заголовочных файлах. Что касается строк 1 и 4 в предыдущем фрагменте кода, главный заголовочный файл — amp.h, а основные типы добавляются к существующему пространству имен concurrency. Никакой дополнительной подготовки или варианта компиляции для использования C++ AMP больше не требуется. Теперь добавим функцию do_it перед main (рис. 1). Рис. 1. Функция do_it, вызываемая из main 52 void do_it()
53 {
54 // Строки и столбцы для матрицы
55 const int M = 1024;
56 const int N = 1024;
57
58 // Создаем хранилище для матрицы указанных размеров
59 vector<int> vA(M * N);
60 vector<int> vB(M * N);
61
62 // Заполняем матричные объекты
63 int i = 0;
64 std::generate(vA.begin(), vA.end(), [&i](){return i++;});
65 std::generate(vB.begin(), vB.end(), [&i](){return i--;});
66
67 // Выходное хранилище для матричных вычислений
68 vector<int> vC(M * N);
69
70 perform_calculation(vA, vB, vC, M, N);
76 }В строках 59, 60 и 68 код использует объекты std::vector как плоские контейнеры для каждой матрицы, хотя на самом деле вам нужно было бы работать с двухмерным типом. Но об этом позже. Важно понимать использование лямбда-выражений в строках 64–65, передаваемых в метод std::generate для заполнения двух векторных объектов. В этой статье предполагается, что вы умеете работать с лямбдами в C++. Например, вы должны моментально понять, что, если бы переменная i захватывалась по значению (модификацией списка захвата [capture list] либо как [i], либо как [=] и использованием ключевого слова mutable), то каждый член вектора инициализировался бы нулевым значением! Если вы не слишком уверенно используете лямбды (великолепное дополнение к стандарту C++ 11), пожалуйста, прочитайте сначала в MSDN Library статью «Lambda Expressions in C++»(msdn.microsoft.com/library/dd293608) и только потом возвращайтесь сюда. Функция do_it вызывает perform_calculation, которая кодируется так: 7 void perform_calculation(
8 vector<int>& vA, vector<int>& vB,
vector<int>& vC, int M, int N)
9 {
15 for (int i = 0; i < M; i++)
16 {
17 for (int j = 0; j < N; j++)
18 {
19 vC[i * N + j] = vA[i * N + j] + vB[i * N + j];
20 }
22 }
24 }В этом упрощенном примере сложения матриц стоит обратить внимание, что многомерность матрицы теряется из-за линеаризованного хранения матрицы в объекте vector (вот почему вместе с объектами vector приходится передавать измерения матрицы). Более того, в строке 19 выполняются забавные арифметические операции с индексами. Этот момент был бы еще очевиднее, если бы вам потребовалось суммировать подматрицы этих матриц. До сих пор никакого кода C++ AMP не было. Теперь, изменив функцию perform_calculation, вы увидите, как можно приступить к введению некоторых типов C++ AMP. В последующих разделах вы узнаете, как полностью задействовать C++ AMP и ускорить ваши параллельные алгоритмы обработки данных. Array_view<T, N>, extent<N> and index<N>В C++ AMP введен тип concurrency::array_view для обертывания контейнеров данных — его можно рассматривать как смарт-указатель. Он представляет данные как прямоугольники, смежные в наименьшем значащем измерении (least-significant dimension). Причина его существования станет понятной позднее, а сейчас вы увидите некоторые аспекты его применения. Давайте изменим тело функции perform_calculation следующим образом: 11 array_view<int> a(M*N, vA), b(M*N, vB);
12 array_view<int> c(M*N, vC);
14
15 for (int i = 0; i < M; i++)
16 {
17 for (int j = 0; j < N; j++)
18 {
19 c(i * N + j) = a(i * N + j) + b(i * N + j);
20 }
22 }Эта функция, которая компилируется и выполняется на центральном процессоре, дает тот же вывод, что и раньше. Единственное различие — беспричинное объявление объектов array_view в строках 11 и 12. В строке 19 по-прежнему используется хитрая индексация (пока), но теперь объекты vector (vA, vB и vC) заменены на объекты array_view (a, b, c), и доступ к элементам осуществляется через функцию-оператор array_view (вместо использования оператора индексирования вектора, но об этом мы поговорим позже). Вы должны сообщить array_view тип элемента обертываемого им контейнера через аргумент-шаблон (int в данном случае); контейнер будет передан как последний аргумент конструктора (например, переменная vC типа vector в строке 12). Первый аргумент конструктора — число элементов. Вы также можете указать число элементов с помощью объекта concurrency::extent, и тогда строки 11 и 12 можно изменить так: 10 extent<1> e(M*N); 11 array_view<int, 1> a(e, vA), b(e, vB); 12 array_view<int, 1> c(e, vC); Объект extent<N> представляет многомерное пространство, где ранг (rank) передается как аргумент-шаблон. В этом примере аргумент-шаблон равен 1, но ранг может быть любым значением, большим 0. Конструктор extent принимает размер каждого измерения, представляемого объектом extent, как показано в строке 10. Затем объект extent можно передать конструктору объекта array_view для определения его формы (shape), как видно в строках 11 и 12. В эти строки я также добавил в array_view второй аргумент-шаблон, указывающий, что этот объект представляет одномерное пространство (как в более раннем примере кода); эту операцию я мог бы безопасно пропустить, потому что 1 — это значение ранга по умолчанию. Теперь, зная эти типы, вы можете внести дальнейшие модификации в эту функцию, чтобы она обращалась к данным более естественным образом в мире матриц: 10 extent<2> e(M, N);
11 array_view<int, 2> a(e, vA), b(e, vB);
12 array_view<int, 2> c(e, vC);
14
15 for (int i = 0; i < e[0]; i++)
16 {
17 for (int j = 0; j < e[1]; j++)
18 {
19 c(i, j) = a(i, j) + b(i, j);
20 }
22 }Изменения в строках 10–12 сделали объекты array_view двухмерными, поэтому нам потребуются два индекса для доступа к любому элементу. Код в строках 15 и 17 обращается к границам extent через его оператор индексирования (subscript operator) вместо прямого использования переменных M и N; инкапсулировав форму в extent, вы можете использовать этот объект в любом месте своего кода. Важное изменение присутствует в строке 19, где больше не требуется хитрой арифметики. Индексация теперь осуществляется гораздо более естественным образом, делая весь алгоритм намного более читаемым и удобным в сопровождении. Если бы array_view был создан с помощью трехмерного extent, тогда функция-оператор ожидала бы передачи трех целочисленных значений для доступа к элементу, по-прежнему в порядке от наибольшего значащего измерения к наименьшему. Есть также способ индексации array_view через единственный объект, передаваемый его оператору индексирования. Объект должен иметь тип concurrency::index<N>, где N совпадает с рангом extent, с помощью которого был создан array_view. Позднее я покажу, как можно передавать объекты index, а пока создадим один такой объект вручную, чтобы получить представление о них и увидеть их в действии. Для этого модифицируйте тело функции так: 10 extent<2> e(M, N);
11 array_view<int, 2> a(e, vA), b(e, vB);
12 array_view<int, 2> c(e, vC);
13
14 index<2> idx(0, 0);
15 for (idx[0] = 0; idx[0] < e[0]; idx[0]++)
16 {
17 for (idx[1] = 0; idx[1] < e[1]; idx[1]++)
18 {
19 c[idx] = a[idx] + b[idx];
//19 //c(idx[0], idx[1]) = a(idx[0], idx[1]) +
b(idx[0], idx[1]);
20 }
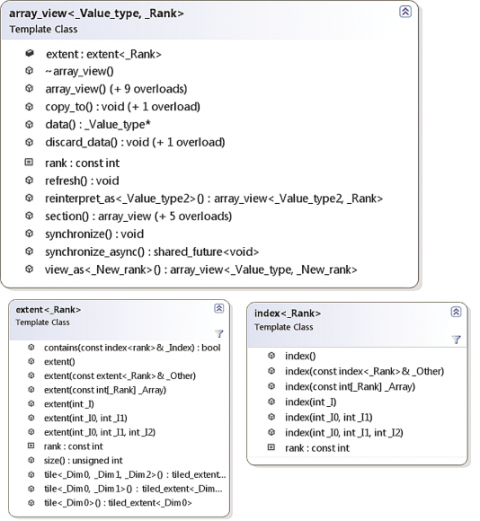
22 }Как видно из строк 14, 15, 17 и 19, интерфейс у типа concurrency::index<N> очень похож на тип extent с тем исключением, что index представляет точку в N-мерном пространстве, а не N-мерное пространство. Оба типа — extent и index — поддерживают ряд арифметических операций через перегрузку операторов, например операцию приращения (increment operation), показанную в предыдущем примере. Ранее переменные циклов (i и j) использовались для индексации в array_view, а теперь их можно заменить одним объектом index в строке 19. Это демонстрирует, как с помощью оператора индексирования в array_view можно указывать нужный элемент одной переменной (в данном примере — idx типа index<2>). К этому моменту вы получили базовое представление о трех новых типах, вводимых C++ AMP: array_view<T,N>, extent<N> и index<N>. На самом деле их возможности шире, как показано на диаграммах классов на рис. 2.
Настоящая мощь и истинные причины использования этого многомерного API заключаются в том, что он позволяет выполнять ваши алгоритмы на ускорителе с высокой степенью распараллеливания обработки данных, например на GPU (графическом процессоре). Для выполнения вашего кода на ускорителе вам нужна входная точка в этот API, а также способ проверки на этапе компиляции того, что вы используете подмножество языка C++, которое может эффективно работать на таком ускорителе. Parallel_for_each и restrict(amp)API, который инструктирует исполняющую среду C++ AMP принять вашу функцию и выполнить ее на ускорителе, — новая перегруженная версия concurrency::parallel_for_each. Она принимает два аргумента: объект extent и лямбду. Объект extent<N>, с которым вы уже знакомы, используется для того, чтобы определить, сколько раз будет вызываться лямбда на ускорителе, и вы должны предполагать, что каждый раз это будет происходить в отдельном потоке, вызывающем ваш код, потенциально параллельно безо всяких гарантий соблюдения порядка. Например, extent<1>(5) приведет к пяти вызовам лямбды, переданной вами в parallel_for_each, тогда как extent<2>(3,4) — к 12 вызовам той же лямбды. В реальных алгоритмах обычно планируются тысячи вызовов лямбды. Эта лямбда должна принимать объект index<N>, который вам уже известен. У объекта index должен быть тот же ранг, что и у объекта extent, переданного в parallel_for_each. Разумеется, значение index при каждом вызове вашей лямбды будет другим — это позволяет вам различать разные вызовы вашей лямбды. Значение index можно было бы рассматривать как идентификатор потока. Ниже приведен код, отражающий то, что я описал на данный момент в отношении parallel_for_each: 89 extent<2> e(3, 2);
90 parallel_for_each(e,
91 [=](index<2> idx)
92 {
93 // Код, выполняемый на ускорителе. Он параллельно
94 // вызывается множеством потоков по одному разу
95 // для каждого индекса, "содержащегося" в extent e,
96 // и индекс передается через idx.
97 // Следующее всегда истинно:
98 // e.rank == idx.rank
99 // e.contains(idx) == true
100 // и функция вызывается e.size() раз.
101 // Для данного случая двухмерного пространства
(.rank == 2)
102 // эту лямбду вызывают e.size() == 3*2 = 6 потоков.
103 // Шесть значений idx, передаваемых лямбде:
104 // { 0,0 } { 0,1 } { 1,0 } { 1,1 } { 2,0 } { 2,1 }
105 }
106 );
107 // Код, выполняемый центральным процессором
(как строки 91 и меньше)Этот простой код без важного добавления в строку 91 не компилируется: error C3577: Concurrency::details::_Parallel_for_each argument #3 is illegal: missing public member: 'void operator() (Concurrency::index<_Rank>) restrict(amp)' В теле лямбды (строки 92–105) можно использовать все, что разрешает полный язык C++ (в варианте, поддерживаемом компилятором Visual C++). Однако в текущих архитектурах графических процессоров нельзя применять определенные аспекты языка C++, поэтому вы должны указывать, какие части вашего кода должны удовлетворять этим ограничениям (чтобы еще при компиляции обнаруживать нарушения любых правил). Эти указания должны присутствовать в лямбде и сигнатурах любых других функций, вызываемых из лямбды. Поэтому строку 91 нужно изменить так: 91 [=](index<2> idx) restrict(amp) Это важнейшее новое языковое средство из спецификации C++ AMP, добавленное в компилятор Visual C++. Функции (в том числе лямбды) можно аннотировать с помощью restrict(cpu) (неявным образом действует по умолчанию) или restrict(amp), как показано в предыдущей строке кода, или их комбинацией, например restrict(cpu, amp). Других вариантов нет. Аннотация становится частью сигнатуры функции, поэтому она участвует в перегрузке; это было одним из важных мотивов при разработке этой функциональности. Когда функция аннотируется restrict(amp), она проверяется на соответствие набору ограничений, и, если хотя бы одно из них нарушается, компилятор сообщает об ошибке. Полный набор ограничений документирован в блоге по ссылке bit.ly/vowVlV. Одно из ограничений restrict(amp) для лямбд заключается в том, что они не могут захватывать переменные по ссылке (см. пример ближе к концу статьи), а также указатели. С учетом этого ограничения, глядя на последний листинг кода с parallel_for_each, вы вполне логично спросите: «Если захват по ссылке запрещен и нельзя захватывать указатели, то как же увидеть результаты (т. е. желательные побочные эффекты) от лямбды? Любые изменения, вносимые в переменные, которые захватываются по значению, окажутся недоступными во внешнем коде, как только выполнение лямбды завершится». Ответом на этот вопрос служит уже знакомый вам тип: array_view. Объект array_view разрешается захватывать в лямбде по значению. Это и есть ваш механизм передачи данных в обоих направлениях. Просто используйте объекты array_view для обертывания настоящих контейнеров, затем захватывайте объекты array_view в лямбде для доступа и заполнения, а потом обращайтесь к соответствующим объектам array_view после вызова parallel_for_each. Сводим все воединоС новыми знаниями вы можете теперь пересмотреть более раннюю версию суммирования матриц на центральном процессоре (ту, где использовались array_view, extent и index) и заменить строки 15–22 на следующее: 15 parallel_for_each(e, [=](index<2> idx) restrict(amp)
16 {
19 c[idx] = a[idx] + b[idx];
22 });Как видите, строка 19 осталась прежней, а двойной вложенный цикл с ручным созданием объекта index в границах extent заменен вызовом функции parallel_for_each. При работе с дискретными ускорителями, имеющими собственную память, захват объектов array_view в лямбде, переданной parallel_for_each, приводит к созданию копии нижележащих данных в глобальной памяти ускорителя. Аналогично после вызова parallel_for_each, когда вы обращаетесь к данным через объект array_view(в этом примере — через c), данные копируются обратно в хост-память из памяти ускорителя. Вы должны знать, что, если вам нужно обращаться к результатам из array_view c через исходный контейнер vC (а не через array_view), то следует вызывать метод synchronize объекта array_view. Код будет работать и в таком виде, поскольку деструктор array_view вызывает synchronize за вас, но любые исключения тогда будут теряться, поэтому я советую вызывать synchronize явным образом. Так что добавьте где-нибудь за вызовом parallel_for_each такое выражение: 23 c.synchronize(); Обратное (поддержание в array_view самых новых данных из их исходного контейнера, если в него вносятся какие-то изменения) достигается через метод refresh. Еще важнее, что копирование данных по шине PCIe (в типичном случае) может обойтись очень дорого, поэтому вы наверняка предпочтете копировать данные только в необходимом направлении. В одном из предыдущих листингов вы можете модифицировать строки 11–13 и указать, что нижележащие данные объектов array_view a и b следует копировать в ускоритель (но не копировать обратно) и что нижележащие данные array_view c не надо копировать в него. Необходимые изменения выделены в следующем фрагменте полужирным: {Для верстки: в этом листинге нужно сохранить выделение полужирным} 11 array_view<const int, 2> a(e, vA), b(e, vB); 12 array_view<int, 2> c(e, vC); 13 c.discard_data(); Однако даже с этими изменениями алгоритм суммирования матриц недостаточно «жаден» до вычислительных ресурсов, чтобы перевесить издержки копирования данных, поэтому на самом деле он не годится на роль кандидата для распараллеливания с помощью C++ AMP. Я воспользовался им только для того, чтобы научить вас базовым вещам! Используя этот простой пример, вы теперь сможете распараллеливать другие алгоритмы, которые действительно требуют очень интенсивных вычислений. Один из таких алгоритмов — перемножение матриц. Пожалуйста, проверьте себя безо всяких комментариев от меня, понимаете ли вы следующую последовательную реализацию алгоритма перемножения матриц: void MatMul(vector<int>& vC, const vector<int>& vA,
const vector<int>& vB, int M, int N, int W)
{
for (int row = 0; row < M; row++)
{
for (int col = 0; col < N; col++)
{
int sum = 0;
for(int i = 0; i < W; i++)
sum += vA[row * W + i] * vB[i * N + col];
vC[row * N + col] = sum;
}
}
}…и соответствующую реализацию с применением C++ AMP: array_view<const int, 2> a(M, W, vA), b(W, N, vB);
array_view<int, 2> c(M, N, vC);
c.discard_data();
parallel_for_each(c.extent, [=](index<2> idx) restrict(amp)
{
int row = idx[0]; int col = idx[1];
int sum = 0;
for(int i = 0; i < b.extent[0]; i++)
sum += a(row, i) * b(i, col);
c[idx] = sum;
});
c.synchronize();На моем лэптопе перемножение матриц с применением C++ AMP выполняется более чем в 40 раз быстрее, чем последовательный код для M=N=W=1024. Освоив базовые вещи, вы наверняка задаетесь вопросом, как выбрать ускоритель для выполнения своего алгоритма после его реализации с использованием C++ AMP. Рассмотрим это в следующем разделе. Accelerator и accelerator_viewЧастью пространства имен concurrency является новый тип accelerator. Он представляет устройство в системе, которое может использовать исполняющая среда C++ AMP, и в первом релизе это аппаратное обеспечение с установленным драйвером DirectX 11 (или эмуляторы DirectX). При запуске исполняющая среда C++ AMP перечисляет все ускорители и на основе внутренней эвристики выбирает один из них в качестве ускорителя по умолчанию. Вот почему в предшествующем коде вам не приходилось напрямую иметь дело с ускорителями — ускоритель по умолчанию выбирался автоматически. Если вы хотите перечислить ускорители и даже самостоятельно выбрать тот, который будет использоваться по умолчанию, сделать это очень легко, как показано в коде на рис. 3. Рис. 3. Выбор ускорителя 26 accelerator pick_accelerator()
27 {
28 // Получаем все ускорители, известные исполняющие среде
C++ AMP
29 vector<accelerator> accs = accelerator::get_all();
30
31 // Пустой ctor (конструктор) возвращает ускоритель,
выбранный исполняющей средой по умолчанию
32 accelerator chosen_one;
33
34 // Выбираем один из ускорителей, например тот,
который не эмулируется
35 auto result = std::find_if(accs.begin(),
36 accs.end(), [] (accelerator acc)
37 {
38 return !acc.is_emulated; //.supports_double_precision
39 });
40 if (result != accs.end())
41 chosen_one = *(result); // блок else опущен
42
43 // Выводим его описание (подсказка:
анализируйте и другие свойства)
44 std::wcout << chosen_one.description << std::endl;
45
46 // Задаем его ускорителем по умолчанию...
в одном процессе можно вызывать только его
47 accelerator::set_default(chosen_one.device_path);
48
49 // ...или просто возвращаем его
50 return chosen_one;
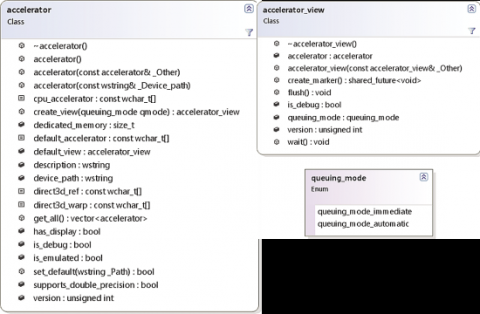
51 }В строке 38 показано, как опрашивать одно из многих свойств ускорителей; остальные свойства приведены на рис. 4.
Если вам нужно, чтобы разные вызовы parallel_for_each использовали разные ускорители, или если у вас есть какие-то иные причины для явного указания ускорителя вместо задания одного глобального по умолчанию для всего процесса, тогда вы должны передавать объект accelerator_view в parallel_for_each. Это возможно, потому что в parallel_for_each есть перегруженная версия, принимающая accelerator_view в качестве первого параметра. Чтобы получить объект accelerator_view, достаточно вызвать default_view объекта accelerator, например: accelerator_view acc_vw = pick_accelerator().default_view; Помимо оборудования, совместимого с DirectX 11, существует три особых ускорителя, которые становятся доступными при использовании C++ AMP:
Разбиение на блоки и рекомендуемые материалыСамая важная тема, не охваченная в этой статье, — разбиение на блоки (tiling). Разбиение на блоки дает на порядки большее быстродействие по сравнению с методиками кодирования, которые мы изучали до сих пор, и потенциально способно обеспечить еще больший выигрыш. Соответствующий API состоит из типов tiled_index и tiled_extent, а также типа tile_barrier и класса хранилища tile_static. Также имеется перегруженная версия parallel_for_each, которая принимает объект tiled_extent и чья лямбда принимает объект tiled_index. Внутри лямбды разрешается использовать объекты tile_barrier и переменные tile_static. О разбиении на блоки читайте в моей второй статье по C++ AMP, которая публикуется в этом номере. Остальное вы можете изучить самостоятельно с помощью публикаций в блогах и онлайновой документации MSDN:
ЗаключениеВ этой статье я познакомил вас с основами современного C++ API для параллельной обработки данных, который позволяет выражать ваши алгоритмы так, чтобы задействовать колоссальные возможности графических процессоров. C++ AMP спроектирован так, что он сможет без проблем работать и с будущим оборудованием. Вы узнали, как несколько типов (array_view, extent и index) помогают работать с многомерными данными, используя единственную глобальную функцию (parallel_for_each); она обеспечивает выполнение вашего кода, начиная с лямбды с restrict(amp) на ускорителе (который можно указывать через объекты accelerator и accelerator_view). Помимо реализации в Microsoft Visual C++, технология C++ AMP предоставляется сообществу как открытая спецификация, которую может реализовать кто угодно на любой платформе. Исходный код можно скачать по ссылке code.msdn.microsoft.com/mag201204CPPAMP.
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|