В конце 1980-х умные ребята из Калифорнийского Университета в Беркли дали миру RAID. Сначала эта аббревиатура расшифровывалась как Redundant Array of Inexpensive Disks (резервный массив недорогих дисков), но корпорации вскоре изменили ее на Redundant Array of Independent Disks – резервный массив независимых дисков (видимо, для того, чтобы избавиться от предположений, что продукты RAID должны быть недорогими). Но вне зависимости от названия, RAID стал промышленным стандартом и подготовил надежность компьютерного хранения к эпохе Интернета.
До RAID хранение данных в компьютерах было запутанным и не очень надежным. После того, как был придуман RAID, стали появляться различные архитектуры, обозначавшиеся номерами, от RAID-0 и RAID-1 до RAID-6. Некоторые производители нумеровали свои продукты номерами больше 6, но это патентованные архитектуры, на самом деле представляющие собой гибриды семи оригинальных архитектур. Ниже предлагаются краткие описания каждой из шести оригинальных архитектур RAID. Но сначала я дам некоторый обзор терминов, связанных с RAID и с компьютерным хранением в целом.
Чередование данных
Чередование данных – это техника, в которой блок данных сегментируется на множество блоков, так чтобы последовательные блоки могли записываться на физически различные устройства. Например, если у нас есть большой документ, который нужно сохранить и у нас два жестких диска, соответствующим образом настроенные (подробности далее), мы может разделить документ на несколько частей. Первая часть документа пишется на диск №1, в это время диск №2 готовится к операции записи. После завершения операции первым диском, вторая часть документа записывается на диск №2, и в это же время диск №1 готовится к следующей операции записи. Это может сэкономить уйму времени, ведь при операциях записи не нужно будет ожидать, пока головка диска переместится в нужную позицию. Документ или любой другой тип блок данных можно разделить на любое количество частей; выбор этого количества обычно производится программно с целью максимизировать преимущества ситуации, когда не нужно ждать перемещения головки диска.
Четность
Четность используется для коррекции ошибок. В хранении данных она работает почти так же, как и в коммуникационных протоколах вроде TCP/IP. С блоком данных заданного объема связан бит четности. Который может иметь значения '1' или '0' в зависимости от того, четное или нечетное количество битов, равных '1', есть в этих данных. Если при чтении данных бит четности неправильный, очевидно, что где-то в процессе чтения\записи произошла ошибка. Конечно, как и в случае коммуникационных протоколов, несколько ошибок могут вернуть бит четности в корректное состояние. Поэтому нельзя использовать четность как единственный метод определения ошибок.
Mirroring – «зеркалирование»
Техника «зеркалирования» полностью соответствует своему названию. Один жесткий диск называется зеркалом другого жесткого диска в том случае, если его логическое представление полностью соответствует логическому представлению второго. Процесс зеркалирования может проводиться различными способами: синхронно, асинхронно или полусинхронно.
Теперь, когда у нас есть понимание основной терминологии, мы переходим к краткому описанию каждой из семи базовых конфигураций архитектуры RAID.
RAID-0
RAID-0 основывается только на чередовании данных и не предоставляет никакой отказоустойчивости. Конфигурации типа RAID-0 всего лишь чередуют данные для записи, и все диски в массиве RAID предназначаются для увеличения скорости чтения/записи. Таким образом можно достигнуть значительного увеличения производительности.
RAID-1
RAID-1 представляет собой нечто противоположное RAID-0, поскольку он основывается на зеркалировании данных. Если в массив RAID-1 входит два диска, значит, один из них будет полной логической копией другого. Этим достигается хорошая отказоустойчивость на случай ошибок в одном из дисков. Такой тип конфигурации может дать увеличение производительности чтения, если операционная система многопоточная и поддерживает параллельный поиск. Параллельный поиск, как и следует из названия; представляет собой возможность искать информацию из нескольких источников.
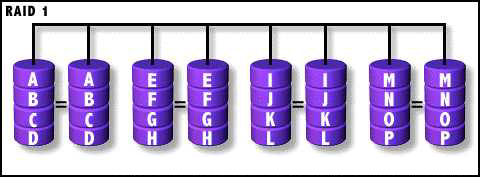
Рисунок 1: Конфигурация RAID-1 (с разрешения bytepile.com)
RAID-2
RAID-2 реализует чередование данных на уровне битов, где каждый последующий бит сохраняется на ином диске в массиве RAID. Архитектура RAID-2 также реализует улучшенную схему четности – четность по Хеммингу. В отличие от базовой схемы четности, которую я описывал выше, четность по Хеммингу помогает определить четное количество ошибок при определенных условиях. Поскольку четность по Хеммингу определяет две ошибки, существует возможность корректировать ошибку, если она одна. Подробно о коде Хемминга можно прочитать по ссылке: http://www.ee.unb.ca/tervo/ee4253/hamming.shtml.
RAID-3
Архитектура RAID-3 реализует схему чередования, похожую на схему в RAID-2, за исключением того, что в RAID-3 чередование осуществляется на уровне байтов: каждый последующий байт записывается на другой диск массива RAID. RAID-3 также использует четность, хотя в данном случае для каждого байта используется простая четность, а биты четности хранятся на специальном диске массива RAID.
RAID-4
RAID-4 реализует чередование на уровне блоков данных и вычисляет четность для каждого блока, храня эти биты на соответствующем диске. В этой архитектуре диски работают независимо, и, следовательно, операционная система может обращаться к ним параллельно. При этом диск, отвечающий за хранение битов четности, может стать слабым звеном в процессе чтения. По этой причине конфигурация RAID-4 используется нечасто.
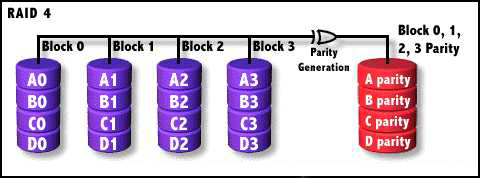
Рисунок 2: Архитектура RAID-4 (с разрешения bytepile.com)
RAID-5
Архитектура RAID-5 идентична RAID-4 за исключением того, что информация о четности распределяется между всеми дисками, устраняя, таким образом, слабое звено. Архитектура RAID-5 требует, чтобы как минимум все диски массива RAID, за исключением одного, функционировали. То есть, архитектура RAID-5 устойчива к ошибкам одного диска. Пользователь начнет терять данные только после того, как откажут два и более дисков. Однако, после потери одного из дисков, массив становится таким же уязвимым, как и в конфигурации RAID-0. Если массивы RAID-5 используются для больших центров данных, существует большая опасность потери данных в период времени, пока диагностируется потеря диска и он заменяется; это пример ситуации, когда требуется RAID-6.
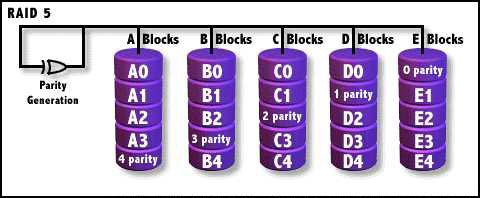
Рисунок 3: Архитектура RAID-5 (с разрешения bytepile.com)
RAID-6
Конфигурация RAID-6 похожа на RAID-5, за исключением того, что тут происходит дублирования распределенной четности. Это позволяет массиву восстанавливать данные после ровно двух отказов дисков. Значительность этой архитектуры особенно проявляется в больших центрах данных, когда диагностируется отказ одного из дисков. В то время, пока диагностируется отказ диска и происходит его замена, массивы данных в конфигурации RAID-6 все еще устойчивы к сбоям, что дает центрам данным большую степень целостности данных.
Как я уже упоминал, существуют и другие нестандартные архитектуры для массивов RAID. Некоторые из самых обычных необычных (разве такое бывает?) архитектур представляют собой комбинации вышеперечисленных. Например, некоторые системы реализуют архитектуру RAID-0+1 или даже RAID-1+0. Эти архитектуры пытаются объединить преимущества отдельных видов архитектур, минимизируя при этом их недостатки. Часто они преуспевают в этой цели, правда, за счет увеличения сложности.
Вот вам и общие объяснения архитектуры RAID. Как обычно, если у вас появились вопросы, пишите мне на электронную почту, и я постараюсь ответить вам как можно скорее.