Оптимизация ИС путем последовательной (модуль за модулем) оптимизации пользовательских модулей, наверно, представляет собой самый эффективный путь. Но такая оптимизация, скорее всего, потребует очень продолжительного времени, которого, как правило, у заказчика нет. Не получив быстрого результата, заказчик вообще можем принять решение о прекращении проекта.
Также вряд ли устроит заказчика стоимость такой оптимизации. Следовательно, необходимо сформировать критерии удовлетворительной работы пользователей, начав оптимизацию с наиболее критических модулей.
Определение списка модулей, в свою очередь, ведет к необходимости проведения опроса пользователей. Таким образом, необходимо затратить существенное время еще до принятия заказчиком решения о направлении движения и стоимости работ. Получается замкнутый круг: нельзя указать стоимость, направление и продолжительность работ, не предприняв достаточно затратного обследования.
Данная статья показывает, как используя формулу для расчета времени отклика, с минимальными временными затратами:
- Оценить возможность оптимизации ИС на системном уровне;
- Определить наиболее “проблемные” сессии;
- Определить сессии, создающие наибольшую нагрузку на систему;
- Определить время выполнения бизнес-транзакций.
Собранные данные являются основой для принятия решения о направлении оптимизации: прикладного ПО или оптимизации на системном уровне. В случае принятия решения о выполнении оптимизации прикладного ПО собранные данные уже содержат критерии для включения трассировки пользовательских сессий. На основании собранных данных можно представить бизнес-план оптимизации системы с указанием:
- Продолжительности и состава работ: списка модулей для оптимизации;
- Достигаемого результата: возможного ускорения;
- Стоимости работ.
При принятии решения об ускорении какой-либо информационной системы (ИС) возникает вопрос – что, собственно говоря, необходимо ускорять? Варианта может быть два:
- не устраивает работа ИС в целом или
- есть конкретные жалобы на тот или иной модуль.
Благодаря работам Cary Millsap [1], достаточно ясно, как оптимизировать конкретный модуль: следует включать трассировку и анализировать ее вывод. Mr. Millsap полагает, что указать модули для оптимизации должен заказчик. Но такой подход обладает рядом недостатков. Во-первых, реакция на жалобы пользователей - это реактивный подход, а хотелось бы иметь возможность предупреждения подобных ситуаций (проактивный подход). Во-вторых, список модулей может оказаться достаточно велик, а общая причина крыться в недостаточно производительном дисковом массиве. В этом случае оптимизация модуль за модулем может оказаться слишком долгой, дорогой и поэтому невостребованной.
Если нас не устраивает работа ИС в целом, выделение конкретных модулей может стать весьма сложной задачей. В компаниях не всегда существуют согласованные бизнес-требования к времени выполнения. А сбор таких требований, их согласование – предмет отдельного обследования. Если же требования существуют, не обязательно существует система регистрации недовольства пользователей (help desc). Возможна и такая ситуация, когда все смирились с существующим положением вещей и уже не считают нужным обращаться в службу help desc.
Таким образом, в идеале следует самостоятельно оценить текущую загрузку ИС, возможности оптимизации ИС на системном уровне, собрать список модулей, с указанием их влияния на ИС. А затем уже сравнить полученные данные с требованиями заказчика.
Произвести необходимые оценки удобнее всего, построив профиль для каждой сессии пользователя. Профиль сессии позволит оценить время отклика пользователя, и таким образом оценить время выполнения бизнес-операций.
Построенный профиль сессии показывает:
- общую продолжительность работы сессии,
- время реальной работы,
- число транзакций,
- распределение времени обслуживание и времени ожидания,
- а также статистику сессии.
Статистика сессии: физический ввод/вывод, логический ввод/вывод, сетевой ввод/вывод, потребление ресурсов
Session info : -------------- Os user / Oracle user / Machine :DSBOOK\dsvolk / DSVOLK / GPVK\DSBOOK Module / Program :SQL*Plus / sqlplusw.EXE Responce time: -------------- Total (s) / Work time (s) / Transactions : 34.00 / 23.40 / 1 Service (s) / Wait (s) / Unaccounted time (s) : 1.25 / 21.40 / .75 Service (%) / Wait (%) / Unaccounted time (%) : 5.34% / 91.45% / 3.21% Session stats: -------------- IO (Mb)/ Cache Memory (Mb)/ Net IO (Mb) : 10.20 / 6.34 / 1.92 Total work : -------------- PGA Memory usage (Mb) / Total changes(Mb): 4.99 / .03 |
Для понимания данной статьи необходимо быть знакомым с формулой времени отклика:
Время отклика = Время обслуживания + Время
ожидания
(Response Time = Service Time + Wait Time)
Данные формула была впервые опубликована в работе [2] (“The COE perfomance method”). Время обслуживания может быть получено из динамических представлений V$SYSSTAT или V$SESSTAT как компонента “CPU used by this session”:
select a.value “Total CPU time” from v a where a.name = ‘CPU used by this session’;
Время ожидания может быть получено из динамических представлений V$SYSTEM_EVENT и V$SESSION_EVENT, суммируя все времена ожидания, за исключением некоторых из них:
select sum(time_waited) “Total Wait Time”from v where event not in ();
Мы можем несколько улучшить нашу формулу, понимая, насколько аккуратно Oracle накапливает времена. Так в "Oracle Database Reference 10g Release 2 (10.2)" для статистики CPU used by this session сказано: если пользовательский вызов завершился быстрее, чем 10 мс, то к статистике будет добавлено 0 мс. Также известно, что подобная “неаккуратность” может происходить в сильно перегруженных серверных комплексах.
Для событий ожидания действует такая же логика: если ожидания было менее 1 мкс для Oracle9i, Oracle10g и менее 1 мс для версии Oracle8i то в результате будет записан 0.
Таким образом, следует записать:
Время отклика =
Время обслуживания + Время ожидания + Неучтенное время
(Response Time = Service Time + Wait Time +
Unaccounted Time)
Unaccounted Time представляет собой ошибку измерений. Если в результате анализа, окажется что Unaccounted Time составляет значительный процент от времени ожидания, следует обнаружить и исключить причину такого поведения.
2.1. Время отклика на уровне экземпляра
Время отклика на уровне экземпляра удобнее всего получить из отчета statspack с помощью следующего запроса:
select event, time, pctwtt from
(
select 'Responce time' event
, (:tcpu*10000 + :twt)/1000000 time
, to_number('100') pctwtt
from dual
Union
select 'Service time' event
, (:tcpu*10000)/1000000 time
, decode(:twt + :tcpu*10000, 0, 0,
100
* :tcpu*10000
/ (:twt + :tcpu*10000)
) pctwtt
from dual
union
select 'Wait time' event
, (:twt)/1000000 time
, decode(:twt + :tcpu*10000, 0, 0,
100
* :twt
/ (:twt + :tcpu*10000)
) pctwtt
from dual
)
order by pctwtt desc;
|
К сожалению, результат представляет собой “среднюю температура по больнице”, а именно, показывает общую ситуацию, которая для отдельных сессий может сильно отличаться. Поэтому построение распределение времени отклика для отдельных сессий очень полезно.
2.2. Время отклика на уровне сессии
Можно построить формулу распределения времени отклика для сессии, воспользовавшись динамическими представлениями v$session_event и v$mystat
На уровне сессии будет интересно получить не только распределение времени отклика, но и определить источник наибольших ожиданий. Однако, большое кол-во событий ожидания (более 800 в версии Oracle10g) и статистик (более 300 в Oracle10g) сильно затрудняет дальнейший анализ. Поэтому для упрощения дальнейшего анализа можно перейти к классам событий ожидания и статистики.
Так, функция apt_stat_class_t (p_statname varchar2 ) return varchar2 возвращает класс статистики, а функция apt_event_class_t (p_event varchar2 ) return varchar2 возвращает класс ожидания. Надо отметить, что классы событий ожидания не совпадают с классами, введенными в версии 10g, и это сделано намеренно.
Таким образом, время ожидания получается из v$session_event :

А время обслуживания из v$mystat:

Как заметит внимательный читатель, на самом деле статистика содержит не только информацию об использовании CPU. Сведения об использовании другой информации будут приведены в следующих главах.
Как уже упоминалось, на уровне экземпляра вполне достаточно воспользоваться несколько модифицированным отчетом statspack. Установка, сбор данных statspack – это хорошо документированная процедура, не оказывающая большого влияния на работу экземпляра, особенно при условии сбора статистики уровня не более 5.
На уровне сессии задача сбора данных несколько сложнее. В книге [3], "Oracle Wait Interface: A Practical Guide to Performance Diagnostics & Tuning", приводится пример триггера before logoff on database. Действительно, как показывает практика, влияние такого триггера на работающую производственную систему минимально, а собираемая статистика наиболее полна. Однако, сохранение статистики в БД может негативно сказаться на производительности. Поэтому статистика будет сохранять во внешнем текстовом файле в формате csv.
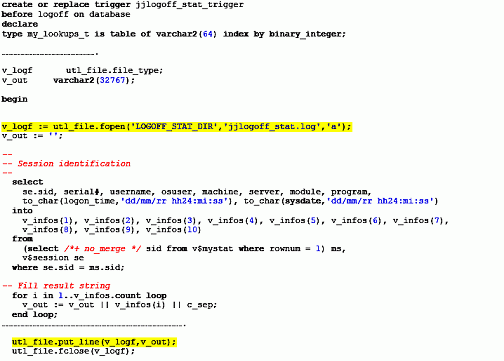 |
4.1 Оценка возможностей оптимизации на системном уровне
Обрабатывая отчеты statspack можно заметить, что время ожидания на уровне экземпляра редко превышает 40-50%. А это значит, что если мы с помощью настроек СУБД или аппаратуры уменьшим время ожидания в 2 раза, наши пользователи, в среднем, получат выигрыш не более 20% -25%. Возможно, отсюда и следует экспериментально известный факт, что с помощью настроек ОС и экземпляра получить более 20% выигрыша в производительности очень сложно.
Хочется отметить, что сложно – не значит невозможно. Хоть и редко, но все еще встречаются случаи, когда неудачное расположение журналов протоколов транзакций (redo logs) тормозит всю систему. Можно привести еще несколько подобных “стандартных” ошибок. В этом случае мы из отчета statspack видим, что время ожидания составляет значительную часть общего времени ответа. Таким образом, перед началом проекта по оптимизации сначала лучше убедиться, что на системном уровне все в порядке. Если необходимо, следует предложить пути системной оптимизации, но указать и ожидаемый эффект.
4.2. Оценка возможностей оптимизации на уровне сессий
Для анализа данных проще всего загрузить собранные с помощью триггера on-logoff данные в СУБД. Начиная с версии Oracle9i можно для подобной операции воспользоваться внешними таблицами (organization external):
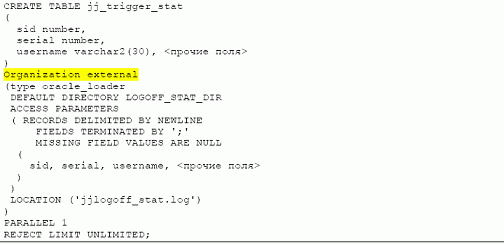 |
4.2.1. Поиск “проблемных” сессий
Получив из statspack среднюю оценку времени ожидания по экземпляру, не стоит отчаиваться. Наша задача как раз и состоит в том, чтобы найти те сессии, у которых времена ожидания составляют значительный процент времени отклика.
Для поиска проблемных сессий, воспользуемся следующим критерием: время ожидания составляет более 60% от общего времени ответа.
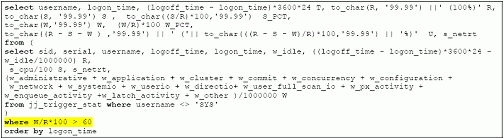 |
Из листинга ниже, мы видим, что есть сессия, у который % ожидания составляет 66.62% от времени ответа.
 |
Для выбранных сессий следует произвести более детальный анализ причин ожидания.
4.2.2 Поиск наиболее тяжелых сессий
Для поиска наиболее тяжелых сессий сначала необходимо определить, какие компоненты (процессор, ввод-вывод, память, сеть) вашей ИС являются узким местом. На листинге ниже приводится пример поиска сессий, выполнивших наибольшее количество чтений.
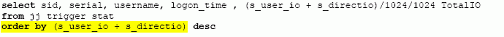 |
На листинге ниже мы видим, что сессия пользователя DWH (warehouse) выполнила наибольшее кол-во физических чтений.
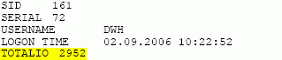 |
4.2.3 Определение времени бизнес транзакции
Рассмотрим упрощенный случай, когда в OLTP системе работают операторы по вводу заявок. Ввод каждой заявки завершается операцией фиксации или отказа (commit или rollback). Тогда, по завершении сессии можно рассчитать время, потраченное на каждую транзакцию по следующей формуле:
Время транзакции = (Время обслуживания + Время ожидания )/кол-во транзакций.
 |
4.2.4 Учет передачи данных по сети
Во время передачи данных клиенту формируется пара сообщений, которые составляют так называемый SQL*Net roundtrip:
|
WAIT #1: nam='SQL*Net message from
client' ela= 5103 p1=1413697536 p2=1 p3=0 |
Обратите внимание, что сообщение from client длится примерно 5 мс, а сообщение to client - 2 мкс, что составляет незначительный процент от общего времени на 1 roundtrip. Однако, проблема состоит в том, что если сессия простаивает, например, в ожидании ввода данных от клиента, ожидание SQL*Net message from client также накапливается. Таким образом, сложно отличить ожидание передачи данных от простоя. К счастью, существует статистика SQL*Net roundtrips to/from client. Если была передача данных, эта статистика увеличивается.
Следовательно, для аккуратного подсчета времени простоя:
Время простоя сессии = Общее время ожидания SQL*Net message from client – Кол-во roundtrip* среднее время 1 rountrip.
Среднее время 1 roundtrip для ИС предлагается определять на основе анализа трассировочных файлов. Для моей локальной системы оно составляет 5 мс.
Таким образом, формула для определения времени ответа сессии преобразуется:
Время отклика - Время простоя = Время обслуживания + Время ожидания + Неучтенное время
На листинге ниже (r2.sql) приводится запрос для определения значений:
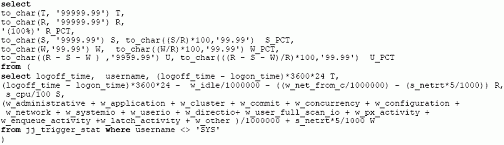 |
Для моей сессии sqlplus, в которой я выполнил большой full scan запрос, а затем просматривал полученные данные, профиль сессии выглядит так:
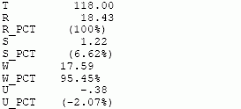 |
Из этого видно: общее время сессии 118 сек, из них только чуть более 18 сек – время работы, а более 95% - время ожидания (передача по сети).
Очевидно, что точность метода зависит от точности определения среднего времени на 1 roundtrip, но другого способа я не знаю.
Приводимый в данной статье метод обладает рядом ограничений, которые следует учитывать при применении.
Так как технически сбор данных выполняется в триггере on-logoff, то информация накапливается только тогда, когда сессия выполняет нормальный выход из БД. Если сессия была прекращена с помощью команды kill, информация об этой сессии собрана не будет. Следует также учитывать, что во время включения триггера часть пользовательских сессий может уже работать, а также что могут существовать сессии, которые не закончатся к моменту выключения триггера. Для более точного учета собираемых данных следует использовать процедуру, собирающую накопленную статистику сессий пользователей до включения/выключения триггера. Так, например, если сессия уже работала на момент включения триггера, то по окончании ее работы из ее статистики необходимо вычесть значения, накопленные до начала работы триггера.
Если сессия выполняет параллельную операцию, то, к сожалению, данные об ожиданиях сессии остаются в подчиненных процессах, которые выполняли реальное чтение данных. Наша сессия испытывает ожидания вида:
 |
По завершении сессии, статистика о кол-ве прочитанных данных и потребленном процессорном времени увеличивается у головного процесса. Сами же подчиненные процессы не попадают в триггер on-logoff, что хорошо – не происходит удвоения данных. Перечисленные выше особенности следует учитывать при анализе причин ожидания.
Не каждая пользовательская сессия обязательно выполняет операции фиксации или отказа (commit или rollback). Вполне могут существовать пользователи, осуществляющие только регулярное чтение данных. В этом случае не получиться рассчитать время их бизнес-транзакций, опираясь на количество фиксаций – их просто нет. Но, в принципе, можно перейти к анализу среднего времени выполнения одного пользовательского вызова (user calls). Конечно, данная ситуация требует более глубокого понимания приложения.
Итак, после определения “проблемных” сессий необходимо выполнить их трассировку. Удобнее всего выполнить такую трассировку в триггере on-logon. Во время сбора информации накоплено достаточно информации о времени выполнения сессии, имени пользователя, наименование программы, чтобы построить условие, которые позволит точно отобрать необходимую сессию.
 |
Триггер on-logoff предоставляет нам широкие возможности для выбора “проблемных” сессий по нескольким критериям. При этом сбор информации не оказывает влияния на работу конечных пользователей. Благодаря возможности одновременного анализа статистики и событий ожидания, можно вести поиск по нескольким направлениям. В тоже время объем собираемой информации существенно меньше, чем объем соответствующих файлов трассировки.
Выводы, полученные с помощью собранной информации, могут позволить Вам избежать значительных временных потерь на опрос пользователей, а сразу предложить к оптимизации действительно “проблемные” модули.
Собранная информация должна быть проанализированы и должны быть сформулированы критерии для включения трассировки “проблемных” модулей.