| Новые программы oszone.net |
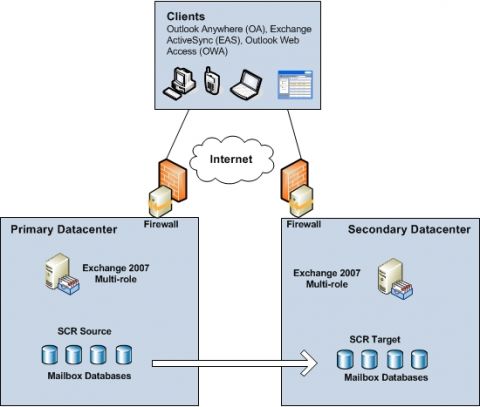
Как раз в то время, когда мы все более-менее привыкли к развертыванию почтовых решений высокой доступности (и зачастую устойчивости сайта) на базе Exchange 2007, команда разработчиков Exchange выпустила продукт Exchange 2010. К счастью история высокой доступности в версии Exchange 2010 практически такая же, как и в версии Exchange 2007? Эй, разве я не начинал с вводной части в другом цикле статей? Да, именно так, но эта вводная часть отлично подходит и для данного цикла статей. Как вы, возможно, заметили в заголовке статьи, в ней основное внимание будет уделено средним организациям. Я расскажу вам, как выполнить необходимые шаги по планированию и развертыванию решения устойчивости сайта Exchange 2010 с помощью четырех серверов Exchange 2010. Затем я сымитирую сбой сайта, чтобы показать шаги, необходимые для того, чтобы перевести почтовое решение в полнофункциональное состояние в другом центре данных. Я хочу сказать, ведь так полезно иметь решение отказоустойчивости сайта, если вы не понимаете шаги обхода отказа, необходимые в случае, если один из центров данных рухнет? Устойчивость сайта в Exchange 2007Когда речь заходила о разработке отказоустойчивой почтовой конфигурации в Exchange 2007, большинство больших предприятий использовало модель активный/пассивный или активный/активный центр данных, посредством которой локально достигалась высокая доступность в центре данных с помощью кластерных почтовых серверов на базе непрерывной кластерной репликации (CCR). То есть, они разворачивали оба узла кластера в кластере CCR в одном основном центре данных, что означало, что в случае сбоев клиенты не подключались к другому центру данных. Аварийная непрерывная репликация (SCR) использовалась для того, чтобы обеспечить решение с устойчивым сайтом, путем репликации лог файлов с кластерного почтового сервера на базе CCR (SCR сервер источника) на один или более кластерных целевых серверов SCR, развернутых в другом активном или пассивном центре данных. Когда стихийное бедствие выводило из строя основной центр данных, кластерные почтовые серверы выводились в рабочий режим на серверах аварийного кластера (SCR targets) в другом центре данных. Балансировка нагрузки и высокая доступность для роли серверов клиентского доступа (CAS) в центре данных обычно достигалась посредством использования балансировки нагрузки Windows Network Load Balancing (WNLB) или решения балансировки нагрузки от сторонних производителей. В Exchange 2007 чаще использовалась WNLB (включая Microsoft IT). Этот подход был описан здесь. Если Exchange 2007 разворачивался в нескольких центрах данных, каждый из которых имел собственное подключение к интернету, в отношении роли Client Access server рекомендовали использовать уникальное пространство имен для каждого центра данных (например, mail.contoso.com и mail.standby.contoso.com). В случае аварии, приводившей к недоступности основного центра данных, внешние и внутренние DNS записи для клиентского доступа указывали на CAS серверы в аварийном центре данных. Устойчивость была встроена в роль транспортного сервера-концентратора (Hub Transport) с тем, чтобы подключение между серверами Hub Transport в организации автоматически выполняло балансировку нагрузки между доступными серверами Hub Transport на сайте Active Directory. Для балансировки нагрузки входящих подключений SMTP с внешних SMTP серверов/клиентов можно было использовать внутреннее LOB приложение и разные сетевые устройства, поддерживающие WNLB или решения балансировки нагрузки от сторонних производителей (WNLB подход описан здесь). Для входящего трафика SMTP с внешних серверов/клиентов можно также использовать старый добрый трюк с MX записью, который я описывал в своем цикле статей о Edge Transport сервере (в 6 части). При обходе отказа с одного центра данных на другой почтовый поток можно было перенаправлять на другой центр данных путем изменения MX записи или службы на базе компьютерного облака, например, FOPE, чтобы она указывала на Hub Transport или Edge Transport серверы в аварийном центре данных. Многие средние предприятия не имели достаточно средств для создания локальной высокой доступности на базе CCR в сочетании с почтовой устойчивостью на уровне сайта посредством SCR. Вместо этого, некоторые организации разворачивали многосайтовый CCR кластер (подобно тому, как описано здесь), зачастую не зная точных преимуществ и особенно недостатков такой конфигурации. Другие организации просто решали не обеспечивать локальной устойчивости сайта и вместо этого разворачивали Exchange 2007 с несколькими ролями (с ролями серверов почтовых ящиков, клиентского доступа и транспортного сервера-концентратора) в каждом центре данных. Затем они включали SCR, чтобы базы данных реплицировались на другой сервер Exchange 2007. Этот сценарий показан на Рисунке 1 ниже. Поскольку в такой конфигурации не использовался функционал обхода отказа на базе кластеров Windows, они могли использовать Windows Server 2003/2008 в версии standard, и пока они не превышали количества центров данных более 5, они даже могли архивировать устойчивость почтовых ящиков с помощью Exchange 2007 версии standard.
Рисунок 1: Устойчивость сайтов во времена Exchange 2007 Хотя это решение было идеально, когда речь заходила об использовании минимально необходимого количества сервера Exchange, важно выделить тот факт, что такое решение не имело действительной высокой доступности на уровне почтовых ящиков (помимо RAID на уровне хранилища). Вместо этого такое решение, по сути своей, было скорее решением восстановления после аварийных ситуаций, нежели решением высокой отказоустойчивости, поскольку оно требовало выполнения некоторых шагов вручную для перехода на аварийный центр данных. Но это давало организациям ощущение защищенности данных почтовых ящиков, и по причине требуемого количества серверов Exchange это было относительно недорогое решение. Плюс ко всему многие организации использовали решения виртуализации Exchange 2007. ОтступлениеБольшинство из вас, вероятно, в курсе того факта, что я уже описывал новые улучшения и изменения, связанные с высокой доступностью, такие как RPC CA массивы, аппаратная балансировка нагрузки, высокая доступность с помощью групп DAG, и я даже написал цикл статей с описанием различных самых распространенных решений устойчивости сайта, доступных в Exchange 2010. Вот их список:
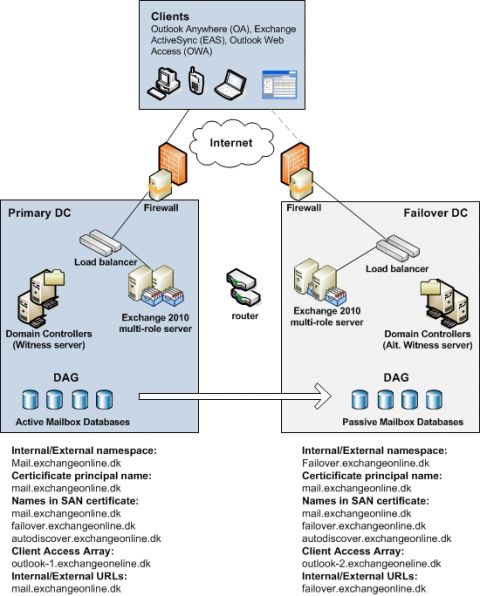
Если вы еще не прочли эти статьи, сейчас самое время это сделать, прежде чем продолжать читать эту статью. Устойчивость сайта в Exchange 2010С выходом Exchange 2010 в свет стало очевидно, что с вышеуказанным решением трудно соперничать не в силу функциональности, а по причине цены. А все потому, что в Exchange 2010 больше не существует SCR. Вместо этого решение Exchange 2010 должно использовать группы DAG, а группы DAG требуют компонент Windows Failover Clustering, что означает, что для репликации баз данных между центрами данных требуется Windows Server 2008/2008 R2 версии enterprise. Когда дело касается потребителей, которые рассматривают переход с решений на базе Exchange 2007, в которых используются кластерные почтовые серверы CCR, все выглядит более благополучно. Вы, возможно, знаете, что CCR требовала минимум 4 Exchange 2007 сервера в каждом центре данных для архивной избыточности на всех уровнях, поскольку нельзя устанавливать никакие роли сервера Exchange за исключением роли сервера почтовых ящиков на узле кластера. Однако в Exchange 2010 мы можем устанавливать другие роли сервера Exchange (за исключением роли пограничного транспортного сервера Edge Transport) на сервер, который входит в группу DAG. Это действительно интересно, так как это помогает нам снизить количество необходимых серверов Exchange. Некоторые из вас могут сказать: «да, но я слышал, что невозможно сочетать Windows Network Load Balancing (WNLB) и DAG на одном сервере, не так ли»? Именно так. И если я не могу сочетать WNLB и DAG, мне все равно придется разворачивать как минимум четыре сервера в каждом центре данных, не так ли? Вовсе необязательно, поскольку именно здесь в игру вступают аппаратные или виртуальные решения балансировки нагрузки. Ну да, скажете вы, я уже посмотрел расценки на несколько решений балансировки нагрузки, и мне не понравилось то, что я увидел. На что я отвечу, что вы смотрели цены не тех производителей, поскольку можно приобрести пару аппаратных компенсаторов нагрузки по приблизительной цене в $3000, что по сравнению с 2 лицензиями на Windows Server 2008 R2 версии standard и 2 лицензиями Exchange 2010 версии standard является вполне демократичной ценой. К тому же, аппаратные или виртуальные решения балансировки нагрузки от сторонних производителей дают вам большинство из тех функций, которые может предложить WNLB (подробную информацию смотрите в этом цикле статей). Плюс ко всему, не стоит забывать, что вы можете использовать гораздо более дешевое хранилище для баз данных Exchange 2010 в отличие от того, что использовалось для Exchange 2007. 7200 RPM Enterprise SATA диски вполне подходят для хранения почтовых данных в силу значительной оптимизации схемы хранения, которая была внесена в Exchange 2010. Для получения балансировки нагрузки и высокой доступности для сервисов Client Access server (CAS) в центре данных мы использовали решение балансировки нагрузки от стороннего производителя. Как и в Exchange 2007, устойчивость была встроена в роль Exchange 2010 Hub Transport с тем, чтобы подключения между серверами Hub Transport внутри организации подвергались автоматической балансировке нагрузки между серверами Hub Transport на сайте Active Directory. Для балансировки нагрузки входящих SMTP подключений с внешних SMTP серверов/клиентов, внутреннего приложения LOB и различных сетевых устройств я использую компенсатор нагрузки стороннего производителя. Итак, решение Exchange 2010, которое должно обеспечивать локальную высокую доступность (HA) и устойчивость на уровне сайта (DR) в средней организации может выглядеть примерно так:
Рисунок 2: Устойчивость сайта в Exchange 2010 (модель активный/пассивный центр данных) В этом сценарии предполагается, что в организации активные пользователи находятся только в одном центре данных. Обратите внимание, что для каждого центра данных используется разное пространство имен и оба центра данных имеют подключение к интернету. Поскольку у нас нет одновременно активных пользователей в обоих центрах данных, мы используем только одну группу DAG. Если организации нужны активные пользователи в каждом центре данных, решение будет выглядеть примерно так:
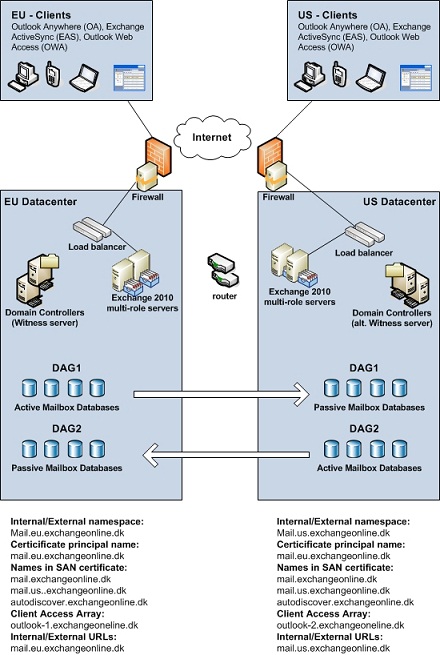
Рисунок 3: Устойчивость сайта в Exchange 2010 (модель активный/активный центра данных) В этом сценарии в обоих центрах данных организации имеются активные пользователи. Обратите внимание, что для каждого центра данных используется разное пространство имен и оба центра данных имеют подключение к интернету. Поскольку у нас есть активные пользователи в обоих центрах данных одновременно, мы используем две группы DAG. Это делается во избежание ситуаций, в которых WAN канал между центрами данных падает и только пользователи одного сайте имеют доступ к почтовым ящикам. Итак, именно эти два сценария мы подробно будем рассматривать в следующих частях этого цикла статей. Прежде чем завершить эту часть давайте взглянем на тестовую среду, используемую в нашей статье. Она включает следующее:
На этом завершим первую часть нашего цикла статей.
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|