| Новые программы oszone.net |
В этом руководстве представлено два способа запуска программ MapReduce в кластере с помощью служб на основе Apache™ Hadoop™ для Windows Azure и описано, как анализировать данные, импортированные в кластер из Excel посредством подключения на основе Hive. Первый способ запуска программ MapReduce — использование файла jar Hadoop с интерфейсом Create Job. Второй способ заключается в применении запроса с ленточным интерфейсом API на языке Pig, представленным в Interactive Console. В первом подходе используется программа MapReduce, написанная на Java, во втором — сценарий Javascript. В этом руководстве также описана процедура загрузки в кластер HDFS файлов, являющихся входными данными для программы MapReduce, и процесс чтения выходных файлов MapReduce из кластера HDFS для получения результатов анализа. Windows Azure Marketplace собирает в режиме реального времени данные, изображения и веб-службы от ведущих коммерческих поставщиков данных и из официальных общедоступных источников информации. Этот сервис упрощает процессы приобретения и использования множества различных данных: демографических, финансовых, связанных с окружающей средой, розничной торговлей, спортом и пр. В данном руководстве демонстрируется загрузка данных в Hadoop на платформе Windows Azure и запрос этих данных с помощью сценариев Hive. Важнейшей функциональной возможностью решения Microsoft для обработки больших данных является интеграция Hadoop с компонентами бизнес-аналитики Microsoft. Наглядный тому пример — подключение Excel к фреймворку хранилища данных Hive в кластере Hadoop. В этом руководстве рассказывается, как использовать в Excel драйвер Hive ODBC для получения доступа к данным и их просмотра в кластере. О чем пойдет речь в данном руководстве:
Руководство состоит из следующих разделов.
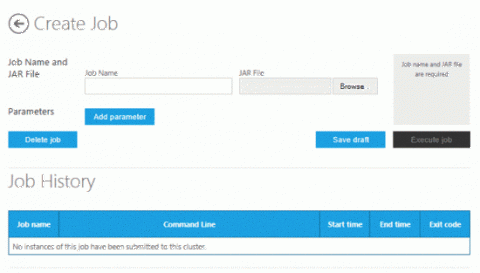
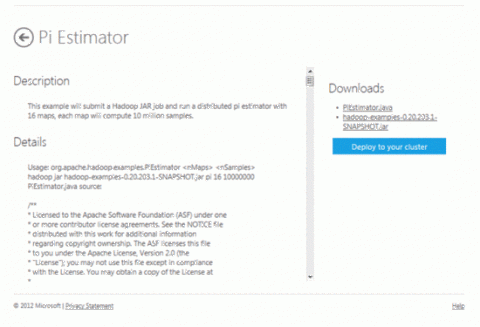
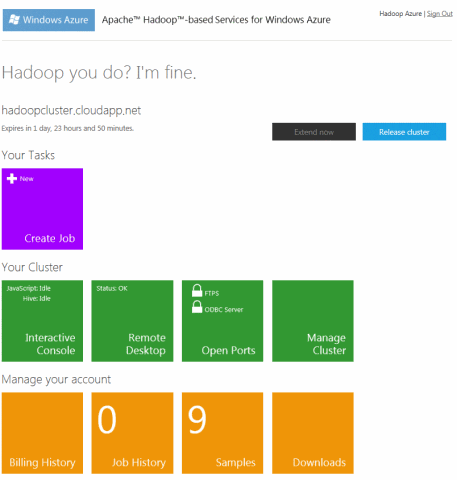
Установка и настройкаПри выполнении заданий этого руководства вам потребуется учетная запись Windows Azure для доступа к Hadoop. Кроме того, необходимо будет создать кластер. Чтобы получить учетную запись и создать кластер Hadoop, следуйте инструкциям раздела «Начало работы с Microsoft Hadoop на платформе Windows Azure» статьи «Вводные сведения о службе на основе Apache Hadoop для Windows Azure ». Запуск базовой программы Java MapReduce с помощью файла jar Hadoop с интерфейсом Create JobНа странице Account в разделе Your Tasks щелкните значок Create Job. Появится пользовательский интерфейс Create Job. Чтобы запустить программу MapReduce, укажите имя задания и используемый файл JAR. Добавьте параметры для указания имени исполняемой программы MapReduce, места расположения входных файлов и файлов кода, а также каталога выходных данных. Рассмотрим использование этого интерфейса для выполнения задания MapReduce на примере расчета числа пи. Вернитесь на страницу Account. В разделе Manage your account найдите значок Samples и щелкните его. На странице Account в разделе Manage your account найдите значок Samples и щелкните его. Щелкните значок примера Pi Estimator в коллекции примеров Hadoop.
На странице Pi Estimator представлены сведения о приложении и загрузках, доступных для программ Java MapReduce, а также файл jar с файлами, необходимыми для развертывания приложений с помощью Hadoop в Windows Azure. В правой части страницы нажмите кнопку Deploy to your cluster, чтобы развернуть файлы в кластере.
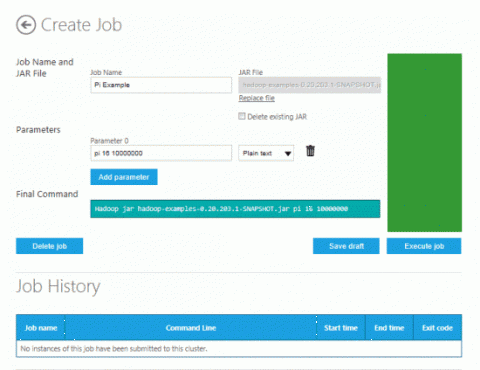
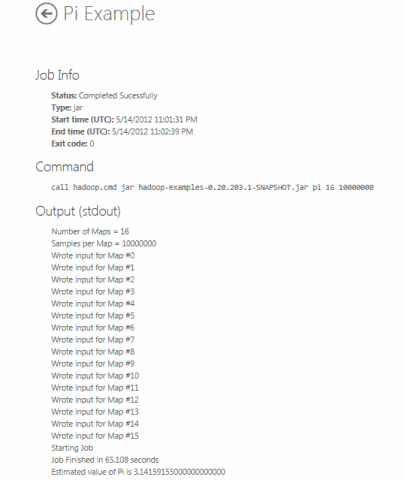
В нашем примере уже введены значения в поля на странице Create Job. Для первого параметра установлено значение по умолчанию «pi 16 10000000». Первое число означает количество создаваемых карт (по умолчанию — 16), второе число — количество примеров, сгенерированных для каждой карты (по умолчанию — 10 миллионов). Таким образом, в этой программе используется 160 миллионов случайных чисел для оценки пи. Final Command создается автоматически на основе указанных параметров и файла jar. Чтобы запустить программу в кластере Hadoop, в правой части страницы нажмите синюю кнопку Execute job. На странице отображается состояние задания, после выполнения оно изменится наCompleted Sucessfully. Результат будет выведен в нижней части раздела Output(stdout). При использовании заданных по умолчанию значений параметров появится следующий результат: число пи = 3,14159155000000000000 (с 8 десятичными знаками после округления).
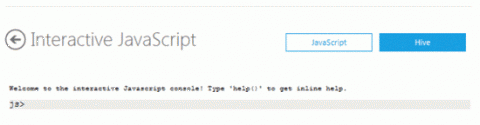
Выполнение сценария JavaScript MapReduce с помощью интерактивной консолиВ этом разделе показано, как выполнять задание MapReduce с запросом, который использует ленточный интерфейс API на языке Pig, представленный в Interactive Console. Для выполнения примера требуется файл входных данных. В примере WordCount, который будет рассматриваться, данный файл уже загружен в кластер. Сценарий .js не нужно загружать в кластер, поэтому на данном шаге будет показана процедура загрузки файлов в HDFS из Interactive Console. Сначала необходимо скачать копию сценария WordCount.js на локальный компьютер. Чтобы загрузить копию в кластер, она должна быть сохранена локально. Щелкните здесь и сохраните копию файла WordCount.js в локальный каталог ../downloads. Кроме того, потребуется скачать электронную книгу «The Notebooks of Leonardo Da Vinci» здесь . Чтобы начать работу с интерактивной консолью JavaScript, вернитесь на страницу Account . В разделе Your Cluster щелкните значок Interactive Console, чтобы открыть интерактивную консоль JavaScript .
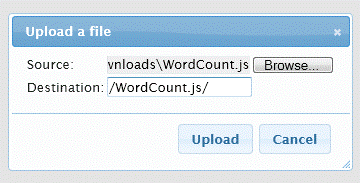
Чтобы загрузить файл JavaScript.js в кластер, введите команду загрузки в консоли js> и выберите в папке загрузок Wordcount.js. Задайте значение параметра Destination./WordCount.js/.
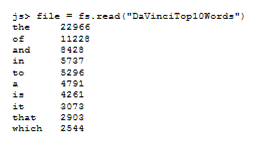
Нажмите кнопку Browse для Source, перейдите к каталогу ../downloads и выберите файл WordCount.js. Введите значение параметра Destination и нажмите кнопку Upload. Повторите эти действия для загрузки файла davinci.txt, используя значение./example/data/ для параметра Destination. Запустите программу MapReduce из консоли js> с помощью следующей команды. Выполните прокрутку вправо и щелкните view log, чтобы просмотреть детальные сведения о выполнении задания. Если возникнет ошибка завершения задания, то в журнале появятся данные диагностики. Чтобы вывести результаты выполнения задания в каталоге DaVinciTop10Words, в командной строке js> задайте команду .
Импорт данных из DataMarket с помощью интерактивной консоли HiveВ браузере откройте страницу Windows Azure Marketplace и войдите с помощью действующего идентификатора Windlows Live ID.
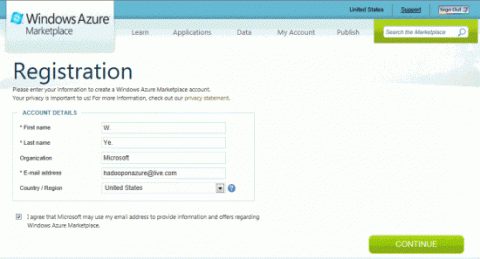
Перейдите на вкладку MyAccount и заполните форму регистрации для открытия учетной записи подписки.
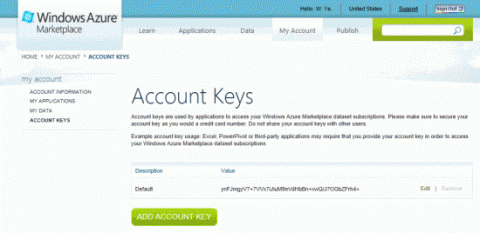
Запомните значение заданного по умолчанию ключа Account, назначенное учетной записи. Ключи Account используются в приложениях для доступа к подпискам на материалы Windows Azure Marketplace.
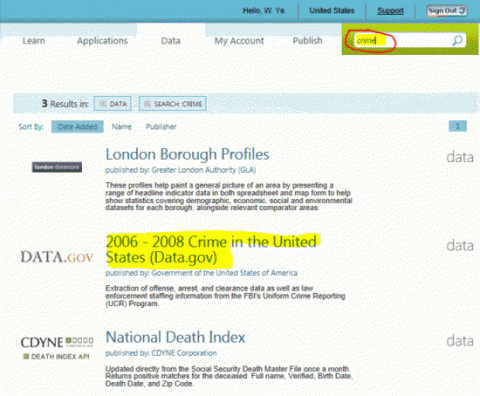
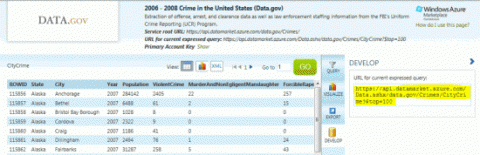
В середине строки меню, рядом с верхней частью страницы, щелкните значок менюData. В верхнем правом углу страницы, в поле поиска по Marketplace, введите crime и нажмите клавишу ВВОД.
Выберите 2006-2008 Crime in the United States (Data.gov).
В правой части страницы нажмите кнопку SUBSCRIBE. Обратите внимание, что подписка бесплатная. Примите условия на странице Sign Up и нажмите кнопку Sign Up.
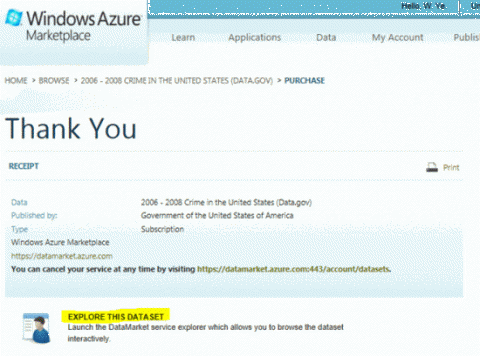
Откроется страница RECEIPT. Нажмите кнопку EXPLORE THIS DATASET, чтобы открыть окно для создания запроса.
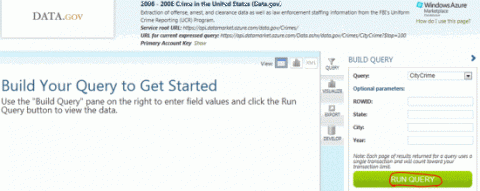
В правой части страницы нажмите кнопку SUBSCRIBE, чтобы выполнить запрос без параметров. Запомните имя запроса и название таблицы, затем перейдите на вкладкуDEVELOP, чтобы посмотреть автоматически созданный запрос. Скопируйте этот запрос.
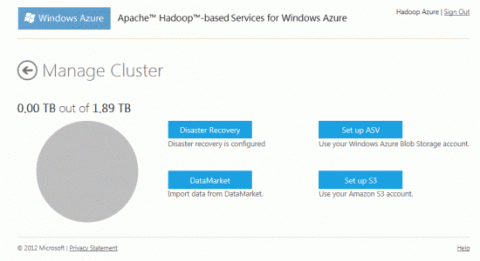
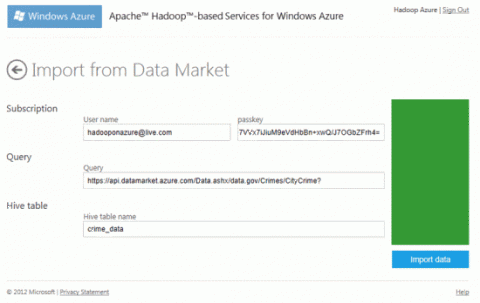
Вернитесь к Hadoop на странице Windows Azure Account и в разделе Your Clusterщелкните значокManage Cluster. Выберите параметр значка DataMarket для импорта данных из Windows Azure DataMarket.
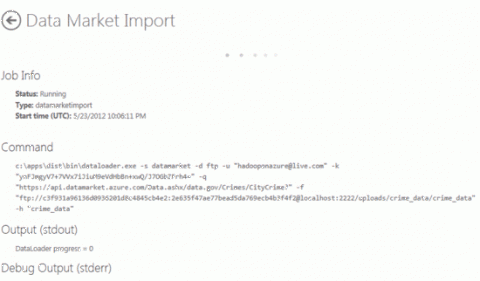
В полях User name, passkey, Query и Hive table name для подписки укажите значения, полученные из учетной записи DataMarket. Имя пользователя — это адрес электронной почты, используемый в идентификаторе Live ID. Значение ключа доступа — это значение по умолчанию ключа учетной записи, назначенное при открытии учетной записи Marketplace. Это также может быть значение параметра Primary Account Key на странице Marketplace Account Details. После ввода всех значений нажмите кнопку Import Data.
Процесс импорта отображается на странице Data Market Import.
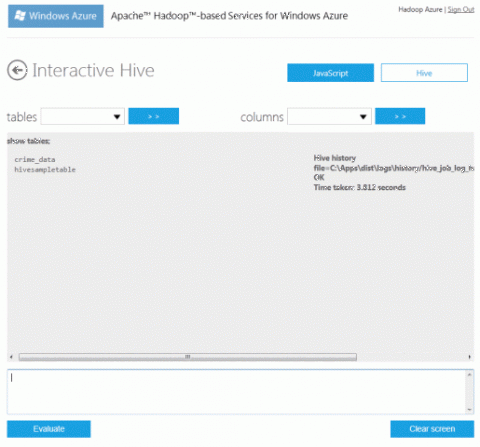
После завершения импорта вернитесь на страницу Account и щелкните значокInteractive Console в разделеYour Cluster. Затем на странице консоли щелкните параметр Hive.
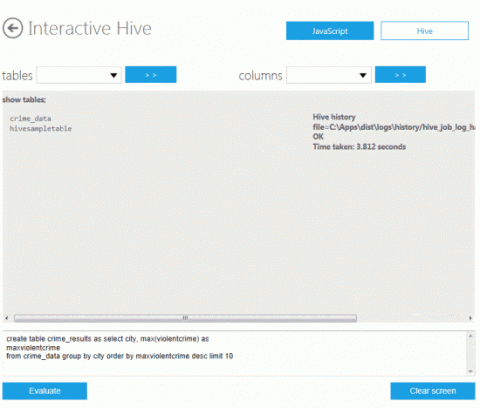
Введите этот фрагмент кода. create table crime_results as select city, max(violentcrime) as maxviolentcrime from crime_data Затем нажмите кнопку Evaluate.
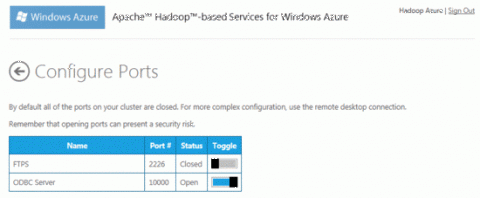
Подключение к данным и запрос данных Hive, сохраненных в кластере, из ExcelВернитесь на страницу Account и в разделе Your Cluster щелкните значок Open Ports, чтобы открыть страницу Configure Ports. Откройте ODBC Server на порту 10000, нажав его кнопку Toggle.
Вернитесь на страницу Account и в разделе Manage your account щелкните значокDownloads . Выберите соответствующий MSI-файл для загрузки драйверов Hive ODBC и надстройки Excel Hive.
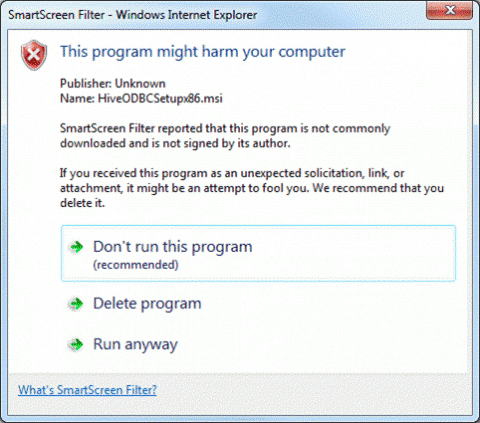
Во всплывающем окне SmartScreen Filter выберите параметр Run anyway.
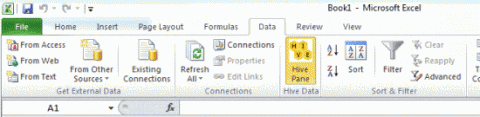
После окончания установки откройте приложение Excel. В меню данных щелкните Hive Panel.
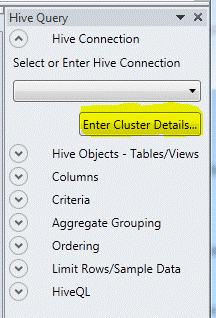
В левой части панели Hive Query нажмите кнопку Enter Cluster Details.
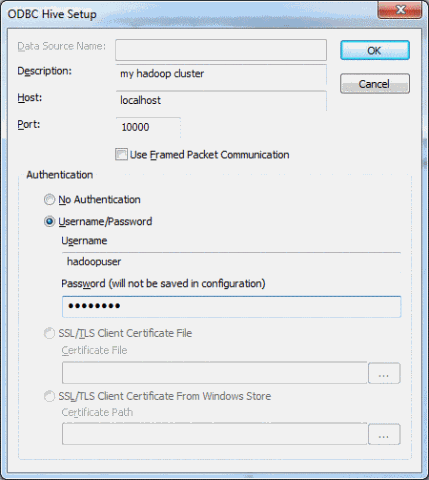
Введите описание кластера, затем localhost в качестве значения Host и 10000 — в качестве номера порта. В разделе Authentication в полях Unsername/Password введите свои учетные данные для Hadoop в кластере Windows Azure. Затем нажмите кнопку OK.
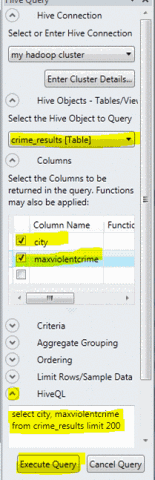
На панели Hive Query в меню Select the Hive Object to Query выберите crime_results. Затем в разделе Columns установите флажки для city и maxviolentcrime. Нажмите кнопку Execute Query.
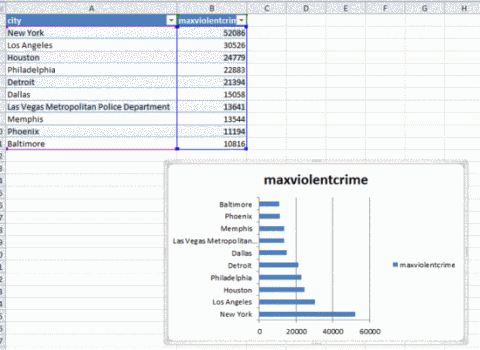
Появится список городов, где совершаются самые жестокие преступления. В меню Insertвыберите параметр Bar, чтобы добавить на страницу столбчатую диаграмму для наглядного представления данных.
ВыводыИз этого руководства вы узнали о двух способах выполнения заданий MapReduce с помощью Hadoop на портале Windows Azure. В первом способе использовался интерфейс Create Job — для выполнения программы Java MapReduce с помощью файла jar. В другом — консоль Interactive Console для выполнения задания MapReduce с помощью сценария .js в запросе Pig. Кроме того, вы узнали, как загружать эти данные в Hadoop на Windows Azure и запрашивать их с помощью сценариев Hive из консолиInteractive Console. И наконец, вы рассмотрели, как применять в Excel драйвер Hive ODBC для доступа к данным, хранящимся в кластере HDFS, и их просмотра.
Теги:
Windows Azure, hadoop.
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|