| Новые программы oszone.net |
Теперь посмотрим на «лошадиные силы», которыми как раз и выделяется R600. Ядро содержит 320 так называемых «единиц потокового вычисления» (stream processing units). Фактически процессоров в ядре 64, а не 320, они сгруппированы по 16 в 4 SIMD-массива (SIMD – Single Instruction on Multiple Data). Такое решение позволяет с большой скоростью проводить однотипные вычисления над большим количеством примитивов, что, собственно, мы и наблюдаем в современной графике (постобработка, шейдеры освещения, тени и т.п.). Каждый процессор способен выполнять 5 инструкций, при этом 4 из них – MUL/ADD (Multiply-Add), и ещё одну сложную трансцендентную инструкцию (SIN, COS, LOG и т.п.). Все инструкции с плавающей точкой выполняются с 32-битной точностью. В составе каждого процессора имеется блок исполнения ветвлений, управляющий выборкой данных и отсылкой их на исполнение, что уменьшает простой конвейеров и упрощает работу диспетчера. Каждый процессор оборудован регистром общего назначения, хранящим исходные данные, временные значения обработки и выходные значения после обработки. Процессоры спроектированы под VLIW-архитектуру (Very Large Instruction Word), каждое слово инструкции может содержать до 6 независимых операций, 5 из них математических и 1 управляющая (Flow Control). Вычислительная мощь SIMD-массивов ядра составляет до 475 ГигаFLOPs по оценке AMD, причём в случае использования массива Crossfire заявляется до 950 миллиардов операций с плавающей точкой в секунду. Так что в ближайшем будущем можно ожидать превышения порога в 1 тераFLOPs на настольном компьютере. Производитель особенно гордится статистическими данными, достигнутыми благодаря как собственно архитектуре, так и технологии производства. С 1 мм2 ядра AMD получает более 1 гигаFLOPs, который стоит менее 1 доллара, а за 1 Вт энергопотребления – более 3,4 ГигаFLOPs. Производительность оценивалась по обработке 32-битным операциям MUL/ADD с плавающей точкой. Для сравнения: производительность двухъядерного Xeon в подобных вычислениях на частоте 3 ГГц составляет около 50 гигаFLOPs. Математическая мощь HD 2000 при правильном применении поражает. Уже довольно долгое время программа распределённых вычислений Folding@Home Кембриджского университета поддерживает архитектуру Radeon X1000, и скорость обработки пакетов заданий силами графических процессоров в разы превышает скорость работы центрального процессора. А ведь у Radeon X1950XTX, бывшего короля графики ATI, всего 48 пиксельных конвейеров, способных обрабатывать по 16 текселей за такт, и 8 вершинных конвейеров. Radeon HD 2900 с точки зрения обработки содержит 320 вычислительных блоков, разделенных на 4 группы, которые в идеале способны проводить до 320 вычислений одновременно. Можете себе представить силу ядра в обработке математики – как научных приложений, так и шейдеров, в первую очередь вершинных и геометрических.
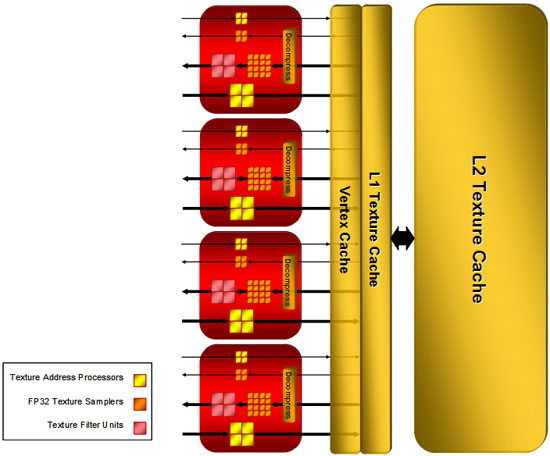
Однако вернёмся к архитектуре и взглянем на текстурные блоки. Radeon HD 2900 оборудован четырьмя такими блоками. Каждый из них содержит 8 процессоров, осуществляющих адресацию текстур, 20 текстурных семплеров, осуществляющих по 1 выборке текстуры за такт, 4 блока фильтрации FP-текстур. В результате Radeon HD 2900 способен за 1 такт адресовать 32 текселя, осуществить выборку 80 значений текстурных координат и билинейную фильтрацию одного 64-битного значения цветовых координат (64-битный HDR). Билинейная фильтрация 128-битных текстур осуществляется за 2 такта. Это в 7 раз быстрее, чем у Radeon X1000. Для текстурных блоков сохранена способность архитектуры X1000, называемая Fetch4: возможность выборки 4 не фильтрованных значений вместо 1 фильтрованного. Текстурные блоки разделяют 256 кбайт кэша второго уровня, при этом без ограничений могут получать доступ к кэшу 1 уровня и вершинному кэшу. ATI вводит новый формат данных для 32-битных HDR – RGBE 9:9:9:5. Поддерживается хранение и использование текстур сверхвысокого разрешения – 8192x8192. Отдельно следует остановиться на работе ядра с вершинными данными. За один такт может быть выбрано до 16 вершин. Кроме того, ATI возвращает в ядро некогда разработанную, но позже упразднённую технологию тесселяции. На ней остановимся подробнее. Как известно, есть несколько способов получить объект с высокой детализацией и затем управлять им. Во-первых, можно «в лоб» создать объект с огромным количеством полигонов, а затем при каждом изменении его положения перерисовывать его. Во-вторых, можно изменять его конфигурацию с помощью вершинного шейдера. В-третьих, можно использовать карту нормалей (normal map), которая будет накладываться на объект со сравнительно более низким числом полигонов и давать более высокую детализацию. Наконец, в последних версиях DirectX возможно использование карт смещения (displacement maps), представляющих собой набор координат ключевых вершин объекта, не требующих просчёта объекта с нуля.
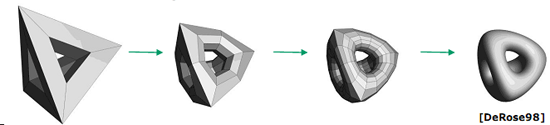
Тесселяция представляет собой рекурсивное применение разделения крупных полигонов на более мелкие математическим путём. В итоге получается, что в памяти видеокарты хранится объект малого разрешения, а выделенный блок тесселяции разделяет его на радикально большее число ключевых координат и работает с ними с помощью карт смещения. Таким способом можно добиться качества объектов (главным образом персонажей), сравнимого с тем, что мы видим в высокобюджетных фильмах. Однако там на просчёт одного кадра уходит огромное количество процессорного времени, а в нашем случае рендеринг производится на лету. При этом тесселяция производится ещё до передачи данных на обработку вершинным шейдером, поэтому просчитанным объектом можно будет управлять по собственному разумению разработчика приложения, без нужды в отдельном инструментарии. Фактически от разработчика больше не требуется долгой и кропотливой работы над созданием высоко детализированной модели и её анимацией. Теперь можно создать модель со сравнительно малым количеством полигонов, анимировать её и создать хорошую карту смещений – всё остальное за вас сделает блок тесселяции, а после рендеринга вы получите модель, сравнимую по качеству с шедеврами, виденными в кино. Для примера посмотрите, что можно сделать из 1 тысячи полигонов:
В механизме тесселяции предусмотрена возможность задавать уровни детализации (LoD, Level of Detail) в зависимости от расстояния до объекта. Это заметно упростит работу видеокарты в современных играх при сохранении отличного качества графики.
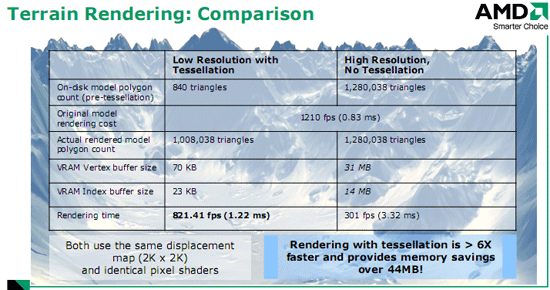
Кроме работы с персонажами тесселяция очень здорово может помочь в работе с ландшафтом. Обратите внимание на сравнение традиционной методики и новых возможностей в следующей таблице:
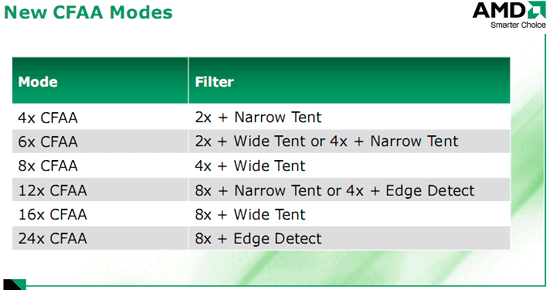
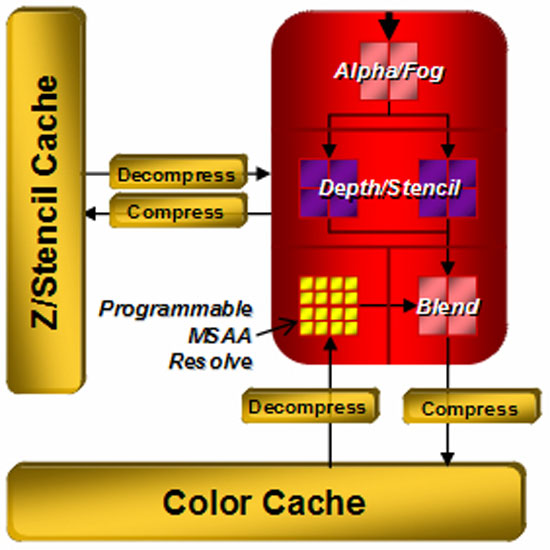
Итак, после обработки SIMD-массивами и текстурными блоками ядро передаёт данные на рендеринг, то есть на сборку и вывод финальной сцены в кадровый буфер. Блоков рендеринга четыре, они, среди традиционной оценки Z-буфера и оценки данных Alpha-координат, содержат блок мультисемплинга. ATI вводит новый метод сглаживания изображения – Custom Filter Antialiasing, представляющий собой программируемый алгоритм, использующий для сглаживания не только набор субпикселей одного пикселя, но и несколько субпикселей соседних пикселей. При этом профиль можно без проблем изменить путём замены фильтра драйвером и получить лучшее качество сглаживания, устранить проблемы с «неудобными» углами и т.п. Особо стоит отметить, что алгоритм обнаруживает грани объектов и использует для их сглаживания больше семплов. Список поддерживаемых образцов – в следующей таблице.
Render Back-end теперь применяет новый метод сжатия 32-битных Z-координат и стенсилей, до 16:1 против 8:1 в прошлых поколениях чипов. При сглаживании сцены методом 8x MSAA степень сжатия может достичь 128:1. Z-буфер может оцениваться дважды, до работы пиксельного шейдера и после неё, в результате объекты, не попадающие на финальную сцену, отбрасываются. Улучшена иерархия Z-буфера, позволяющая ускорить в первую очередь скорость обработки стенсильных теней. На следующем слайде приведено соотношение производительности в обработке стенсильных теней Radeon HD 2900 и Radeon X1950 XTX.
Наконец, после всей обработки, да и на промежуточных стадиях, данные передаются в кадровый буфер, то есть в память видеокарты. И тут AMD/ATI также даёт нам повод для отдельной остановки.
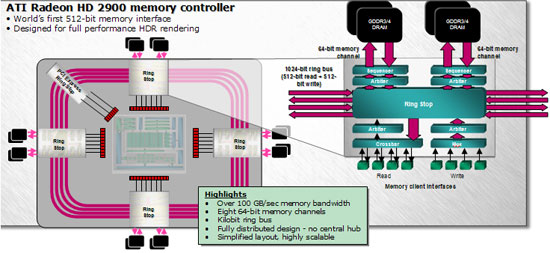
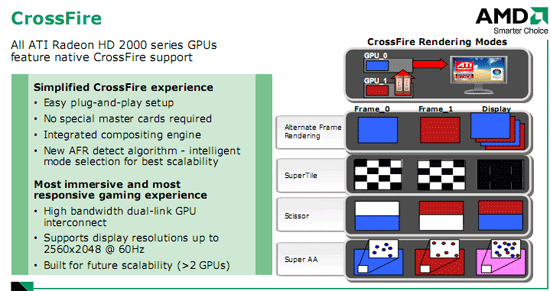
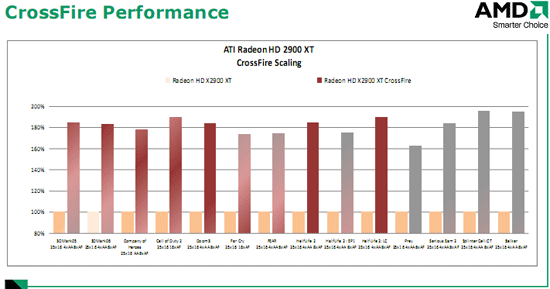
Думаю, многие помнят контроллер памяти Radeon X1000. Решение инженеров ATI очень оригинально и выигрышно, кольцевой контроллер памяти позволяет уменьшить задержки на промежуточных стадиях и упростить организацию доступа к ней на физическом уровне. Однако стоит заметить, что на самом деле в Radeon X1000 контроллер памяти был не полностью кольцевым, он объединял в себе черты традиционного контроллера и кольцевого. В Radeon HD 2000 контроллер памяти полностью сделан по кольцевой схеме. 512-битная шина памяти на самом деле представляет собой как бы 4 шины по 128 бит, объединённые в общую шину. Более того, шина памяти двунаправленная, по 512 бит в каждом направлении, что даёт фактически 1024 бита разрядности. Подключение шины к ядру осуществляется в 4 местах, названных Ring Stop, с шириной двустороннего канала по 64 бита на каждое соединение. Такой дизайн в сочетании с высокоскоростной памятью дает ATI возможность достичь пропускной способности памяти более 100 ГБ/с! Преимуществом полностью кольцевой шины является то, что при проектировании новых ядер инженерам не придётся заново проектировать и контроллер памяти, достаточно организовать интеграцию существующего в новое ядро. Заметно упрощается и проектирование печатных плат и выводов чипа графического процессора, не нужно проводить дорожки в одно место, их можно вывести там, где удобно. В конце остановимся на технологии Crossfire. ATI продолжила благое начинание, представленное в Radeon X1950Pro, и внедрила поддержку Crossfire непосредственно в ядро. Теперь не нужно искать мастер-карту, мучиться с кабелями для объединения видеокарт – Compositing Engine встроен в ядро и позволяет объединить две одинаковые карты обычным мостиком, точно как NVIDIA SLI.
Из нововведений стоит отметить новый алгоритм Alternate Frame Rendering, улучшающий скорость поочередной обработки кадров парой видеокарт. AMD заявляет, что новая версия Compositing Engine специально создавалась для будущей поддержки видеокарт с двумя GPU, что довольно интересно, так как до этого подобные видеокарты были очень редким явлением.
ВыводИтак, как видим, с теоретической точки зрения новая графическая архитектура ATI/AMD получилась вполне удачной. Новые видеокарты абсолютно очевидно ориентированы на графические приложения ближайшего и более отдалённого будущего, в которых намного больше будет именно математических вычислений на основе шейдеров. Особенно это относится к вершинным и геометрическим шейдерам. Также стоит очень внимательно посмотреть на инициативу ATI по внедрению тесселяции в игровую графику. Если разработчики игр её поддержат (а уже сейчас Microsoft Game Studios и Techland сообщают об активной поддержке со стороны AMD при разработке игр), то мы наконец можем надеяться на долгожданную кинематографичность графики в играх при сохранении нормальной скорости обработки. Было бы очень интересно посмотреть не только на технологические демонстрационные ролики AMD и NVIDIA, но и на реальное воплощение их технологий – хотя бы заставки в играх, созданные на их движке и рассчитывающиеся в реальном времени. Отдельно следует остановиться на побочном применении вычислительной мощи Radeon HD 2000 – научных, медицинских и других подобных расчётах. На самом деле не использовать такие ресурсы в целях, как раз требующих именно таких мощностей, было бы кощунством. Мы постараемся в ближайшее время дополнительно акцентировать ваше внимание на возможных методах применения новых видеокарт в подобных целях, благо их совсем не мало. Пока же отметим, что на пресс-конференции в Тунисе, проведённой AMD для журналистов со всего мира, был озвучен доклад, из которого стало ясно, что за подобное применение графических процессоров взялись всерьёз: разработан инструментарий для программирования, совместимый с существующими языками программирования, осуществляется активная и всесторонняя поддержка разработчиков. Немаловажные изменения коснулись встроенного декодера видео, причём настолько значительные, что, по нашему мнению, они достойны отдельного материала. Этим мы в ближайшее время и займёмся, оставайтесь с нами!
Теги:
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|