| Новые программы oszone.net |
По нескольку раз в неделю у меня проcят совета, как эффективно обслуживать рабочую базу данных. Порой вопросы исходят от администраторов баз данных, которые применяют новые решения и ищут помощи в подгонке практики обслуживания под характеристики новых баз данных. Чаще вопросы исходят от людей, которые не являются профессиональными администраторами баз данных, но, по той или иной причине, владеют базой данных или несут за нее ответственность. Я предпочитаю называть их «невольными администраторами баз данных». Задача этой стать состоит в предоставлении учебника по наилучшим вариантам обслуживания баз данных для . Как и в случае с большинством задач и процедур в мире информационных технологий, годящегося на любой случай эффективного решения обслуживания баз данных не существует, но есть несколько ключевых областей, которые почти всегда требуют внимания. Моя личная первая пятерка этих областей, перечисленная без определенного порядка важности:
У необслуживаемой (или плохо обслуживаемой) базы данных могут возникнуть проблемы в одной или нескольких из этих областей, что со временем может привести к плохой работе приложений или даже простоям и потере данных. В этой статье я объясню, почему эти проблемы важны, и покажу некоторые простые пути их смягчения. Мои объяснения будут основаны на SQL Server® 2005, но я также выделю основные отличия, с которыми можно столкнуться в SQL Server 2000 и предстоящем SQL Server 2008. Управление файлами данных и журналовПервая область, которую я всегда рекомендую проверить при принятии управления базой данных – это параметры, связанные с управлением файлами данных и журнала (транзакций). Точнее говоре, следует убедиться, что:
Когда файлы данных и журнала (которые, в идеале, вообще должны быть на разных томах) находятся в одном томе с любым другим приложением, которое создает или расширяет файлы, возникает возможность для фрагментации файлов. В файлах данных избыточная фрагментация файлов может давать небольшой вклад в плохую работу запросов (особенно тех, что просматривают очень большие объем данных). В файлах журналов она может нанести гораздо более серьезный удар по производительности, особенно если автоматическое расширение установлено лишь на очень небольшое увеличение размера файла каждый раз, как в нем возникает потребность. Файлы журнала внутренне разделены на разделы, именуемые виртуальными файлами журнала (Virtual Log Files – VLF), и чем выше фрагментация в файле журнала (я использую здесь единственное число, поскольку наличие нескольких файлов журнала не имеет большого смысла – в базе данных следует держать только один), тем больше число VLF. После того, как число VLF в файле журнала превышает, скажем, 200, может ухудшиться производительность связанных с журналом операций, таких как чтение журнала (скажем, для транзакционной репликации/отката), резервное копирование журнала и даже триггеров в SQL Server 2000 (реализация триггеров изменилось в SQL Server 2005 с журнала транзакций на инфраструктуру версий строк). Что касается размеров файлов данных и журнала, лучше всего создавать их с подходящим первоначальным размером. Для файлов данных при выборе первоначального размера должна приниматься во внимание возможность добавления к базе дополнительных данных в ближайшей перспективе. Например, если первоначальный размер данных равен 50 ГБ, но известно, что в течение следующих шести месяцев будет добавлено еще 50 ГБ данных, имеет смысл сразу создать файл данных размером в 100 ГБ вместо того, чтобы выращивать его до этого размера в течение нескольких месяцев. С файлами журналов дело, увы, обстоит несколько сложнее – необходимо учитывать такие факторы, как размер транзакции (долгосрочные транзакции не могут быть удалены из журнала до своего завершения) и частоту резервного копирования журнала (поскольку именно при нем удаляются неактивные части журнала). Дополнительные сведения приведены в "8 Steps to Better Transaction Log Throughput («8 шагов к улучшению пропускной способности журнала транзакций»)", популярной записи в блоге на SQLskills.com, написанной моей женой, Кимберли Трипп (Kimberly Tripp). После того, как размеры файлов установлены, за ними следует наблюдать в различные моменты, и их следует заранее увеличивать вручную в подходящее время суток. Автоматическое увеличение следует оставить в качестве предосторожности на всякий случай, чтобы файлы могли расти по мере необходимости в случае какого-либо необычного события. Причина, по которой управление файлами не следует целиком оставлять автоматическому увеличению, состоит в том, что автоматическое увеличение небольшими кусками ведет к фрагментации файлов и что автоматическое увеличение может занимать много времени, тормозя работу приложения в неожиданные моменты. Размер автоматического увеличения следует установить на определенное значение, а не на процент, чтобы ограничивать время и место, необходимые для выполнения автоматического увеличения, если оно происходит. Например, в случае 100-гигабайтного файла данных желательно зафиксировать размер автоматического увеличения как 5 ГБ, а не, скажем, 10%. Это значит, что он всегда будет увеличиваться на 5 ГБ вне зависимости от текущего размера файла, а не на объем, увеличивающийся после каждого увеличения файла (10 ГБ, 11 ГБ, 12 ГБ и так далее). Когда журнал транзакций увеличивается (либо вручную, либо через автоматическое увеличение), он всегда инициализируется нулями. Файлы данных имеют то же поведение по умолчанию в SQL Server 2000, но начиная с SQL Server 2005 в них можно включить мгновенную инициализацию файла, которая пропускает инициализацию файлов нулями и, как следствие, делает увеличение и автоматическое увеличение практически мгновенными. В противоположность распространенным представлениям, эта функция доступна во всех выпусках SQL Server. Дополнительные сведения можно найти, введя "instant file initialization" («мгновенная инициализация файла») в указателе электронной документации для SQL Server 2005 или SQL Server 2008. Наконец, следует позаботиться, чтобы никоим образом не было включено сжатие. Сжатие можно использовать для уменьшения размера файла данных или журнала, но это очень грубый, ресурсозатратный процесс, который вызывает широкую логическую фрагментацию просмотра в файлах данных (подробности см. ниже) и ведет к низкой производительности. Я изменил запись о сжатии в электронной документации SQL Server 2005, включив предупреждение об этом. Впрочем, сжатие отдельных файлов данных и журнала вручную может быть допустимо при особых обстоятельствах. Автоматическое сжатие особенно вредно, поскольку оно запускается каждые 30 минут в фоновом режиме и пытается сжимать базы данных, для которых выставлен параметр автоматического сжатия. Этот процесс не вполне предсказуем в том, что он сжимает лишь базы данных с более чем 25% свободного места. Автоматическое сжатие использует массу ресурсов и вызывает понижающую производительность фрагментацию, так что оно нежелательно при любых обстоятельствах. Его всегда следует отключать с помощью: ALTER DATABASE MyDatabase SET AUTO_SHRINK OFF; План регулярного облуживания, включающий выдачу базе данных команды на сжатие вручную, почти столь же плох. Если обнаружится, что база данных постоянно растет после того, как план обслуживания сжимает ее, то это вызвано тем, что базе данных данное пространство нужно для работы. Лучше всего позволить базе данных вырасти до размера стабильного состояния и избегать сжатия вообще. Дополнительные сведения о недостатках использования сжатия, а также кое-какие комментарии по новым алгоритмам в SQL Server 2005 можно найти в моем старом блоге MSDN® на blogs.msdn.com/sqlserverstorageengine/archive/tags/Shrink/default.aspx. Фрагментация индексовПомимо фрагментации на уровне файловой системы и внутри файла журнала, также возможна фрагментация внутри файлов данных, в структурах, хранящих данные таблиц и индексов. Внутри файла данных может произойти два базовых типа фрагментации:
Внутренняя фрагментация – это наличие в странице больших пустых пространств. Как показывает рис. 1, каждая страница в базе данных имеет размер 8 КБ и 96-байтный заголовок; как следствие, страница может хранить примерно 8096 байтов данных индексов или таблиц (конкретные внутренние структуры таблиц и индексов для данных и структур строк можно найти в моем блоге по адресу sqlskills.com/blogs/paul, в категории Inside The Storage Engine («Внутри механизма хранения»)). Пустое пространство может возникнуть, если каждая таблица или запись в индексе превышают по размерам половину страницы, поскольку тогда на странице можно сохранить лишь одну запись. Исправить это очень сложно или невозможно, поскольку для исправления необходимо изменение схемы таблицы или индекса, например, путем изменения ключа индекса на что-то, что не вызывает случайные точки вставки, как это делает GUID.
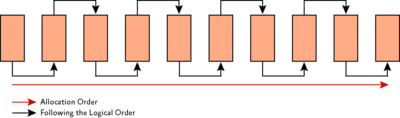
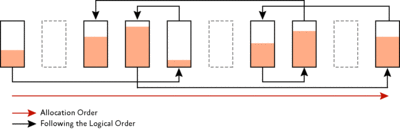
Рис. 1. Структура страницы базы данных Чаще внутренняя фрагментация вызывается изменениями данных, такими как вставки, обновления и удаления, что может оставить на странице пустые места. Неверное распоряжение коэффициентом заполнения также может способствовать фрагментации, подробности приведены в технической документации. В зависимости от схемы таблицы/индекса и характеристик приложения это пустое место может оказаться непригодным для повторного использования после его появления, что может привести к постоянному росту неиспользуемого места в базе данных. Рассмотрим, для примера, таблицу из 100 миллионов строк, где средняя запись имеет размер 400 байтов. Со временем шаблон изменения данных приложения приведет к появлению в среднем 2800 байтов свободного пространства на страницу. Общее пространство, требуемое таблицей, составляет 59 ГБ, это выводится путем следующего расчета: 8096-2800 / 400 = 13 записей на 8-килобайтную страницу, затем делим 100 миллионов на 13, чтобы получить число страниц. Если бы пространство не пропадало, то на одной странице можно было бы уместить 20 записей, что уменьшает общее требуемое пространство до 38 ГБ. Огромная экономия! Неиспользуемое место на страницах данных/индекса может, таким образом, привести к хранению того же объема данных на большем числе страниц. Это не только приводит к большему расходу места на диске, но и значит, что запросу надо провести больше операций ввода/вывода, чтобы прочесть тот же объем данных. И все эти дополнительные страницы занимают больше места в кэше данных, занимая тем самым память сервера. Логическая фрагментация просмотра вызывается операцией, именуемой разбиением страницы. Это происходит, когда запись необходимо вставить на определенную страницу индекса (согласно определению ключа индекса), но на странице недостаточно места, чтобы разместить вставляемые данные. Страница разбивается пополам, и примерно 50% записей перемещаются на свежевыделенную страницу. Эта новая страница обычно не является физически смежной со старой и, следовательно, именуется фрагментированной. Концепция фрагментации просмотра по блокам аналогична. Фрагментация внутри структур таблиц/индексов влияет на возможность SQL Server выполнять эффективные просмотры как по всей таблице/индексу, таки и ограниченные предложением WHERE запроса (такие как SELECT * FROM MyTable WHERE Column1 > 100 AND Column1 < 4000). На рис. 2 показаны свежесозданные страницы индекса со 100-процентным коэффициентом заполнения – страницы полны, и физический порядок страниц совпадает с логическим порядком. На Рис. 3 показана фрагментация, которая может происходить после случайных вставок/обновлений/удалений.
Рис. 2. Свежесозданные страницы индекса без фрагментации, страницы полны на 100%
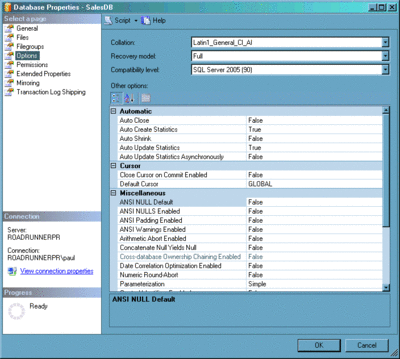
Рис. 3 Страницы индекса, показывающие внутреннюю фрагментацию и фрагментацию логического просмотра после случайных вставок, обновлений и удалений Фрагментацию порой можно предотвратить, изменив схему таблицы/индекса, но, как я упомянул выше, это может быть очень сложным или невозможным. Если предотвращение нереально, существуют способы устранения фрагментации после ее возникновения – в частности, путем восстановления или реорганизации индекса. Восстановление индекса подразумевает создание новой копии индекса (аккуратно сжатой и настолько непрерывной, насколько это возможно, с последующим отказом от старой и фрагментированной). Поскольку SQL Server создает новую копию индекса перед удалением старой, ему требуется свободное место в файлах данных, приблизительно равное размеру индекса. В SQL Server 2000, восстановление индекса всегда проводилось в автономном режиме. Однако в SQL Server 2005 Enterprise Edition восстановление индекса можно выполнить в интерактивном режиме с некоторыми ограничениями. Реорганизация, с другой стороны, использует имеющийся алгоритм для сжатия и дефрагментации индекса; она требует лишь 8 КБ дополнительного пространства для выполнения – и всегда работает в интерактивном режиме. Кстати, в SQL Server 2000 я специально написал код реорганизации как интерактивную, экономящую пространство альтернативу перестройке индекса. В SQL Server 2005 следует обратить внимание на команды ALTER INDEX … REBUILD для восстановления индексов и ALTER INDEX … REORGANIZE для их реорганизации. Этот синтаксис заменяет команды SQL Server 2000 DBCC DBREINDEX и DBCC INDEXDEFRAG, соответственно. Между этими методами есть много различий, влияющих на выбор одного из них, таких как создаваемый объем журнала транзакций, требуемый объем свободного пространства в базе данных и возможность прервать процесс без потери выполненной работы. Технический документ, к котором обсуждаются эти различия, и прочее можно найти на microsoft.com/technet/prodtechnol/sql/2000/maintain/ss2kidbp.mspx. Этот документ основан на SQL Server 2000, но концепции хорошо переносятся на поздние версии. Некоторые пользователи просто решают восстанавливать или перестраивать все индексы каждую ночь или каждую неделю (используя, например, вариант с планом обслуживания) вместо того, чтобы выяснять, какие индексы фрагментированы и какое преимущества даст устранение фрагментации. Хотя это может быть хорошим решением для невольного администратора базы данных, который просто желает применить какое-то решение с минимальными усилиями, это может оказаться очень плохим выбором для более крупных баз данных и систем, где ресурсы в дефиците. Более сложный подход подразумевает использование динамического административного представления sys.dm_db_index_physical_stats (или DBCC SHOWCONTIG в SQL Server 2000) для периодического определения фрагментированных индексов и выбора того, следует ли работать на них, и если да, то как. В данном техническом документе также обсуждается использование этих более узких выборов. Вдобавок, некоторые образцы кода для выполнения этой фильтрации можно найти в примере D записи электронной документации, посвященной динамическому административному представлению sys.dm_db_index_physical_stats в SQL Server 2005 (msdn.microsoft.com/library/ms188917) или примере E записи электронной документации, посвященной DBCC SHOWCONTIG в SQL Server 2000 и далее (на msdn.microsoft.com/library/aa258803). Какой бы метод ни использовался, настоятельно рекомендуется регулярно искать и устранять фрагментацию. Обработчик запросов является частью SQL Server, которая решает, как следует исполнять запрос – а именно, какие таблицы и индексы использовать и какие операции выполнять на них для получения результатов; это именуется планом запросов. В число наиболее важных входных данных этого процесса принятия решений входит статистика, описывающая распределение значений данных для столбцов внутри таблицы или индекса. Очевидно, чтобы быть полезной для обработчика запросов, статистика должна быть точной и свежей, иначе могут быть выбраны непроизводительные планы запросов. Статистика создается путем считывания данных таблицы/индекса и определения распределения данных для соответствующих столбцов. Статистика может быть построена путем проверки всех значений данных для определенного столбца (полной проверки), но ее также можно построить на основе указанного пользователем процента данных (проверки примеров). Если распределение значений в столбце является относительно равномерным, то проверки примеров может быть достаточно, и это делает создание и обновление статистики более быстрым, чем при полной проверке. Обратите внимание, что статистику можно автоматически создавать и поддерживать, включив параметры базы данных AUTO_CREATE_STATISTICS и AUTO_UPDATE_STATISTICS, как показано на рис. 4. Они включены по умолчанию, но тем, кто только что унаследовал базу данных, стоит проверить их, чтобы убедиться. Порой статистика может устареть – в этом случае возможно ее обновление вручную с помощью операции UPDATE STATISTICS для конкретного набора статистических показателей. В качестве альтернативы можно использовать хранимую процедуру sp_updatestats, которая обновляет всю устаревшую статистику (в SQL Server 2000 sp_updatestats обновляет всю статистику вне зависимости от возраста).
Рис. 4. Изменение параметров базы данных через SQL Server Management Studio Если нужно обновлять статистику как часть плана регулярного обслуживания, то нужно помнить об одной хитрости. И UPDATE STATISTICS, и sp_updatestats по умолчанию используют ранее указанный уровень сбора данных (если указан какой-то) – и он может быть ниже, чем полная проверка. Восстановления индекса автоматически обновляют статистику с помощью полной проверки. В случае обновления статистики вручную после восстановления индекса можно получить еще менее точную статистику! Это может произойти, если проверка примеров из обновления вручную перепишет полную проверку, созданную восстановлением индекса. С другой стороны, при реорганизации индекса статистика вообще не обновляется. Опять-таки, многие имеют план обслуживания, обновляющий всю статистику в какой-либо момент до или после восстановления всех индексов – и сами того не зная, они могут оказаться с менее точной статистикой. Если выбрано простое восстановление всех индексов время от времени, то оно позаботится и о статистике. Если выбран более сложный путь с устранением фрагментации, это стоит делать и для обслуживания статистики. Я предлагаю следующее:
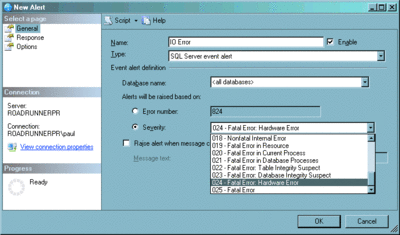
Дополнительную информацию о статистике можно найти в техническом документе "Statistics Used by the Query Optimizer in Microsoft® SQL Server 2005" («Статистика, используемая оптимизатором запросов в Microsoft SQL Server 2005») (microsoft.com/technet/prodtechnol/sql/2005/qrystats.mspx). Обнаружение поврежденийЯ рассказал об обслуживании, связанном с производительностью. Теперь пора переключиться на рассказ об обнаружении повреждений и смягчении последствий. Крайне маловероятно, чтобы в базе данных содержалась совершенно бесполезная информация, которая никого не волнует – так как же можно убедиться, что данные остаются неповрежденными и восстанавливаемыми в случае аварийной ситуации? Подробности сведения воедино полной стратегии аварийного восстановления и высокой доступности выходят за пределы темы этой статьи, но для начала можно сделать несколько простых вещей. Подавляющее большинство повреждений вызываются «оборудованием». Почему оно в кавычках? Ну, оборудование здесь – это на самом деле условное обозначение для «что-то в подсистеме ввода-вывода, под SQL Server». Подсистема ввода/вывода состоит из таких элементов, как операционная система, драйверы файловой системы, драйверы устройств, контроллеры RAID, кабели, сеть и сами диски. Масса мест, где могут возникнуть (и возникают) неполадки. Одной из наиболее распространенных проблем является сбой питания в момент, когда диск ведет запись на страницу базы данных. Если диск не сможет завершить запись, прежде чем у него кончится электричество (или если операции записи кэшируются и резервного источника питания не хватит для очистки кэша диска), результатом может стать незавершенный образ страницы на диске. Это может произойти, поскольку 8-килобайтная страница базы данных на деле состоит из 16 смежных 512-байтных секторов диска. Неполная запись могла записать некоторые из секторов из новой страницы, но оставить некоторые из секторов из образа предыдущей страницы. Такая ситуация называется разорванной страницей. Как можно обнаружить, когда это случается? У SQL Server есть механизм для обнаружения такой ситуации. В него входят сохранение нескольких битов из каждого сектора страницы и запись определенного шаблона на их месте (это происходит непосредственно перед записью страницы на диск). Если при считывании страницы шаблон изменился, то SQL Server знает, что страница «порвана», и выдает ошибку. В SQL Server 2005 и более поздних версиях доступен более полный и способный определить любые повреждения на странице механизм, именуемый контрольными суммами страниц. В него входят запись контрольной суммы всей страницы на страницу прямо перед ее записью и затем ее проверка при считывании только что записанной информации, точно так же, как при обнаружении порванных страниц. После включения контрольных сумм страниц страницу необходимо прочитать из буферного пула, изменить каким-либо образом и записать на диск снова, чтобы она стала защищена контрольной суммой страницы. Так что лучше всего включить контрольные суммы страниц начиная с SQL Server 2005 и далее, а для SQL Server 2000 включить обнаружение разорванных страниц. Чтобы включить контрольные суммы страниц, используйте следующий оператор: ALTER DATABASE MyDatabase SET PAGE_VERIFY CHECKSUM; Чтобы включить обнаружение разорванных страниц для SQL Server 2000, используйте следующий оператор: ALTER DATABASE MyDatabase SET TORN_PAGE_DETECTION ON; Эти механизмы позволяют обнаружить наличие повреждений на странице, но только при чтении страницы. Как можно легко организовать чтение всех распределенных страниц? Лучшим методом для выполнения этого (и обнаружения повреждений любого другого рода) является использование команды DBCC CHECKDB. Вне зависимости от указанных вариантов эта команда всегда будет читать все страницы в базе данных, таким образом заставляя проверять все контрольные суммы страниц или обнаружение порванных страниц. Следует также установить предупреждения, чтобы можно было узнать, когда пользователи сталкиваются с повреждениями при выполнении запросов. Пользователь также может быть уведомлен о всех вышеописанных проблемах, используя предупреждение о ошибках уровня серьезности 24 (рис. 5).
Рис. 5. Установка предупреждения для всех ошибок серьезности 24 Так что другой хорошей рекомендацией является регулярное выполнение DBCC CHECKDB на базах данных для проверки их целостности. Существует много вариантов этой команды и вопросов о том, как часто ее следует выполнять. Увы, технического документа, в котором это бы обсуждалось, сейчас не существует. Однако, поскольку DBCC CHECKDB была основной частью кода, которой я написал SQL Server 2005, я много писал о ней в блогах. См. категорию моего блога "CHECKDB From Every Angle" («CHECKDB со всех сторон»)(sqlskills.com/blogs/paul), в которой имеется много подробных статей, посвященных проверке целостности, рекомендациям и практическим советам. Для невольных администраторов баз данных хорошим правилом является выполнение DBCC CHECKDB после каждого полного резервного копирования базы данных. Я рекомендую выполнять следующую команду: DBCC CHECKDB ('MyDatabase') WITH NO_INFOMSGS,
ALL_ERRORMSGS;
Если эта команда что-то выдает, DBCC нашел повреждения в базе данных. Тогда вопрос превращается в: «Что делать, если DBCC CHECKDB находит повреждения?». Здесь-то на сцене и появляются резервные копии. При возникновении повреждения или иного сбоя наиболее эффективным способов восстановления является восстановление базы данных из резервных копий. Конечно, это предполагает наличие таковых копий и то, что сами они не повреждены. Слишком часто пользователи хотят знать, как заставить серьезно поврежденную базу данных работать вновь, когда у них нет резервной копии. Простой ответ состоит в том, что это невозможно, во всяком случае без потери данных, способной исковеркать всю бизнес-логику и реляционную целостность данных. Так что регулярное резервное копирование весьма рекомендуется. Тонкости использования резервного копирования и восстановления выходят далеко за пределы этой статьи, но позвольте мне дать краткую инструкцию по созданию стратегии резервного копирования. Во-первых, следует регулярно выполнять полное резервное копирование базы данных. Это дает единое состояние на момент времени, до которого затем можно восстанавливать. Полную резервную копию базы данных можно сделать, используя команду BACKUP DATABASE. Примеры имеются в электронной документации. Для дополнительной защиты можно использовать параметр WITH CHECKSUM, который проверяет контрольные суммы (если они есть) читаемых страниц и вычисляет контрольную сумму для всей резервной копии. Следует выбрать частоту, отражающую потерю данных или работ, которую можно себе позволить. Например, резервное копирование всей базы данных раз в день означает, что в случае сбоя может быть потеряна дневная работа в данных. В случае использования лишь полного резервного копирования базы данных следует быть в модели восстановления SIMPLE (обычно именуемой режимом восстановления), чтобы избежать сложностей, связанных с управлением ростом журнала транзакций. Во-вторых, держите резервные копии по нескольку дней на случай, если одна из них будет повреждена – старая резервная копия лучше, чем никакой. Также следует проверять целостность своих резервных копий, используя команду RESTORE WITH VERIFYONLY (опять же, см. электронную документацию). Если при создании резервной копии был использован параметр WITH CHECKSUM, при использовании команды проверки будет проверено, верна ли еще контрольная сумма резервной копии, а также контрольные суммы страниц внутри нее. В-третьих, если ежедневное полное копирование базы данных может привести к недопустимому для компании уровню потерь данных/сделанной работы, возможно, стоит заглянуть в разностные резервные копии базы данных. Разностная резервная копия базы данных основана на полной резервной копии базы данных и содержит запись всех изменений с момента создания последней полной копии (часто считается, что разностные резервные копии являются добавочными – это не так). В качестве примера стратегии можно привести ежедневное снятие полной резервной копии с созданием разностной копии каждые четыре часа. Разностная копия предоставляет вариант восстановления к состоянию на дополнительный момент времени. В случае использования только полного и разностного резервного копирования баз данных также следует использовать модель восстановления SIMPLE. Наконец, наилучшие возможности по восстановлению предоставляет резервное копирование журналов. Оно доступно лишь в моделях восстановления FULL (и BULK_LOGGED) и предоставляет резервные копии всех записей журнала, созданных с момента последнего резервного копирования журнала. Поддержание набора резервных записей журнала, а также периодическое проведение полного (и, возможно, разностного) резервное копирования позволяет восстановить состояние на любой момент времени с точностью до минуты. Платить за это приходится тем, что журнал транзакций растет, пока его не «освобождают», создав резервную копию. В качестве примера стратегии здесь можно привести ежедневное снятие полной резервной копии с созданием разностной копии каждые четыре часа и резервной копии журнала каждые полчаса. Выбор стратегии резервного копирования и организация ее применения могут быть непростыми. Как минимум, следует регулярно выполнять полное резервное копирование базы данных, чтобы убедиться в наличии как минимум одного момента времени, состояние базы данных на который может быть восстановлено. Как можно увидеть, обеспечение работоспособности и доступности базы данных требует выполнения нескольких обязательных задач. Вот мой последний контрольный список для невольных администраторов баз данных, которым досталось управление базами:
Я привел в статье команды T-SQL, но многое можно сделать и из Management Studio. Надеюсь, что я дал вам кое-какие полезные указания по эффективному обслуживанию баз данных. Если у вас есть комментарии или вопросы, отправьте их мне —paul@sqlskills.com.
Теги:
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|